Your Micro SaaS MVP: Building a Minimum Viable Platform, Not Just a Product
Building a Micro SaaS MVP? Don't forget the 'P' for Platform! Learn how to avoid common pitfalls, especially when outsourcing.


Did you know that platform missteps, not just feature flaws, torpedo countless Micro SaaS dreams before they even launch? Some estimates suggest up to 75% of IT projects fail outright or miss crucial objectives. Many founders focus intently on the 'V' – Viable – slicing features thin. They neglect the 'P' – Platform. That's a critical error. Especially when outsourcing.
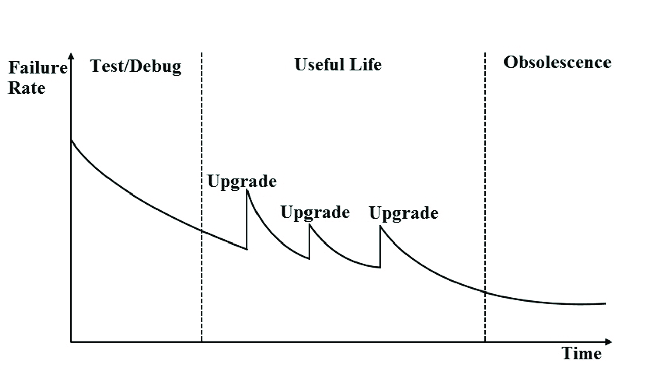
You're building foundations, not just facades. Ship code. Iterate. Survive. But survive smartly. Building a Micro SaaS isn't just about a clever feature loop; it’s about the underlying engine. Get that wrong, and your MVP becomes an MVD: Minimum Viable Dead-end.
This isn't about agile basics or choosing React over Vue. You know that game. This is about the hard-won lessons from the trenches, specifically when entrusting your core platform build to an external team. Let's dissect the common failure points and map a better path – the path we tread at 1985.

The Platform Problem: More Than Meets the Eye
Too many founders treat their MVP infrastructure as an afterthought. Big mistake. They believe "platform" concerns – scalability, security, observability – are "future problems." They aren't. They are now problems disguised as future savings.
Defining the 'P' Beyond the Feature Set
Your MVP isn't just the user-facing feature. It's the entire delivery mechanism. Think authentication, basic data persistence, deployment pipeline, logging. Neglect these, and feature iteration grinds to a halt. Or worse, collapses entirely.
A Gartner analysis (while broadly discussing IT complexity) points towards the hidden costs of neglecting foundational architecture early on. The technical debt accrued by ignoring the platform can cripple velocity faster than any market shift. We saw this firsthand with a promising B2B SaaS client. They outsourced their "MVP" to a low-cost vendor focused only on the core feature. Six months in, they couldn't reliably onboard new tenants. Authentication was brittle, deployments were manual nightmares, and basic logging was non-existent. Debugging took days, not hours. They shipped the feature. They failed the platform. Fixing it cost them double their initial "savings."
Actionable Takeaway: Mandate a "Platform Definition Document" alongside your feature specs for any outsourced MVP. It should minimally cover: Authentication approach, Data storage strategy (and basic schema), Hosting environment, Deployment process (even if manual initially, document it), Logging level 1 (what absolutely must be logged).
Technical Debt Isn't Deferred Payment; It's High-Interest Loan Sharking
"We'll fix it later" is the siren song of failed MVPs. Technical debt, especially at the platform level, compounds viciously. A poorly designed database schema? Minor annoyance at 10 users, catastrophic failure at 1000. No infrastructure-as-code? Every environment change is a snowflake, fragile and unreproducible.
Consider the findings in Stripe's Developer Coefficient report, which highlights how much developer time is wasted on maintenance and bad code. This isn't just about sloppy code; it's often about foundational shortcuts. We inherited a project where the previous team hardcoded everything – API keys, environment variables, database credentials. Deploying to staging required hours of manual changes. Production pushes were prayers. They hit their feature deadline. But the platform was quicksand. Our first sprint wasn't features; it was triage and basic configuration management.
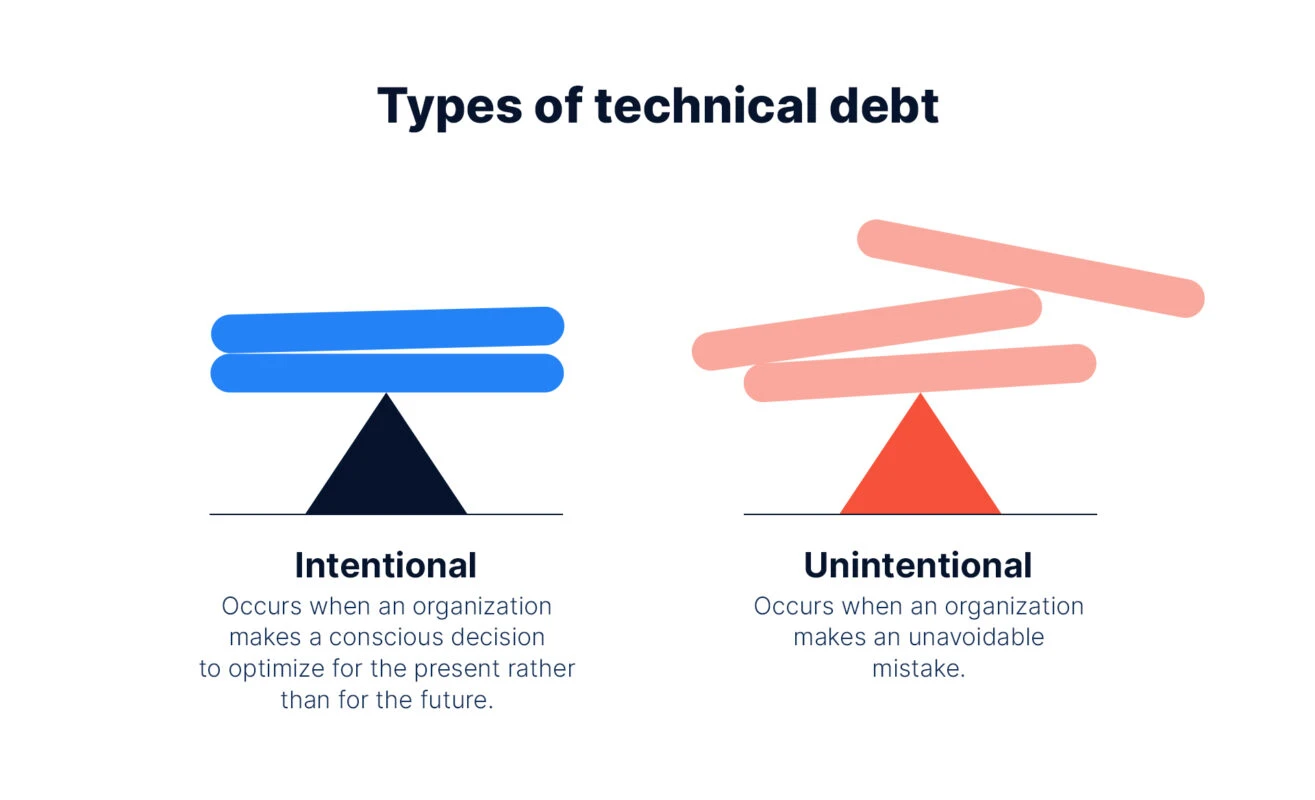
Actionable Takeaway: Institute a "Technical Debt Tax" in sprint planning. Allocate 10-15% of capacity specifically for refactoring or improving foundational elements identified in the previous sprint's retrospective. Make it non-negotiable.
Why Outsourcing Your Platform MVP Often Implodes (And How to Avoid It)
Outsourcing promises speed and cost savings. Often, it delivers neither, especially for platform-centric MVPs. Why? Misaligned incentives, communication chasms, and process theater.
The Myth of the 'Cheap' Offshore Developer
The allure of low hourly rates is strong. Dangerously strong. You aren't buying hours; you're buying outcomes. A $25/hour developer writing code that needs constant rework, lacks tests, and ignores security costs far more than a $100/hour developer building it right (or closer to right) the first time.
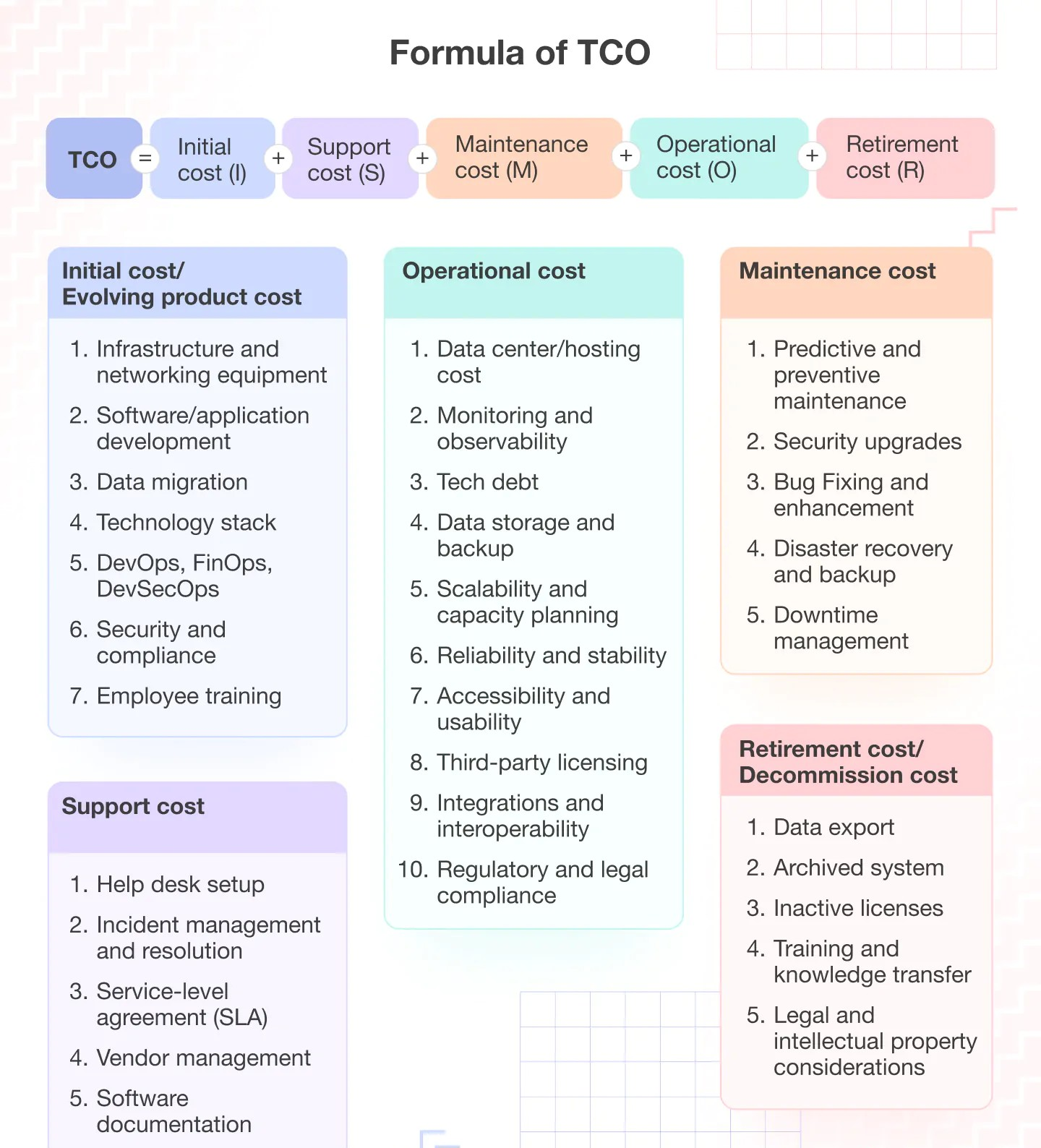
The Total Cost of Ownership (TCO) for software includes not just development hours but debugging, refactoring, infrastructure snafus, security breaches, and lost opportunity cost. Cheap code often maximizes these hidden costs. A FinTech startup came to 1985 after their "cost-effective" offshore team delivered an MVP riddled with security holes (SQL injection vulnerabilities, plain text password storage – the works). The "savings" evaporated instantly facing potential compliance fines and reputational ruin. The platform foundation was rotten. We had to rebuild core components before any new features could be considered.
| Factor | "Cheap" Outsourcing Reality | Strategic Partnering (like 1985) Focus |
| Hourly Rate | Low ($20-$40/hr) | Higher ($80-$150+/hr) |
| Code Quality | Often low, untested, insecure | High, tested, secure by design |
| Rework Needed | High | Low |
| Communication | Often difficult, asynchronous lag | Structured, high-context |
| Process | Opaque, "Agile Theater" | Transparent, outcome-driven |
| Platform Focus | Minimal, feature-only | Foundational, built to evolve |
| True TCO | High (due to hidden costs) | Lower (predictable, less rework) |
Actionable Takeaway: Demand code quality metrics and test coverage reports from week one. Don't rely solely on feature demos. Ask: What's the test coverage? How are secrets managed? Show me the deployment script. If they balk, that's a red flag.
Communication Breakdowns: More Than Just Time Zones
Yes, time zones are a factor. But the real killer is lack of shared context and unspoken assumptions. Vague requirements lead to misinterpretations, especially across cultural divides or when the team lacks deep domain understanding.
Industry studies consistently show communication as a top factor in project failure. While specific stats vary, the theme is constant. We onboarded a client whose previous outsourced team built an entire reporting module based on a misunderstanding of a key business metric. Weeks wasted. Why? The requirements doc was ambiguous, and the team didn't ask clarifying questions – perhaps due to cultural reluctance to challenge or simply lack of engagement. At 1985, we embed a "Clarification Mandate": Assumptions are documented explicitly, and ambiguities must be resolved before coding begins, often requiring synchronous calls despite time differences. No ambiguity survives discovery.
Actionable Takeaway: Implement a "Definition of Ready" for user stories before they enter a sprint. This checklist must include: Clear acceptance criteria, Ambiguities resolved (with documented answers), Dependencies identified, Design/UX mockups attached. No "Ready" check, no sprint entry.
Process Misalignment: Agile Theater vs. Real Progress
"We do Agile." Famous last words. Many outsourced teams perform Agile ceremonies without understanding the principles. Daily standups become status reports, not problem-solving sessions. Retrospectives are blame games or skipped entirely. Sprints deliver activity, not value.
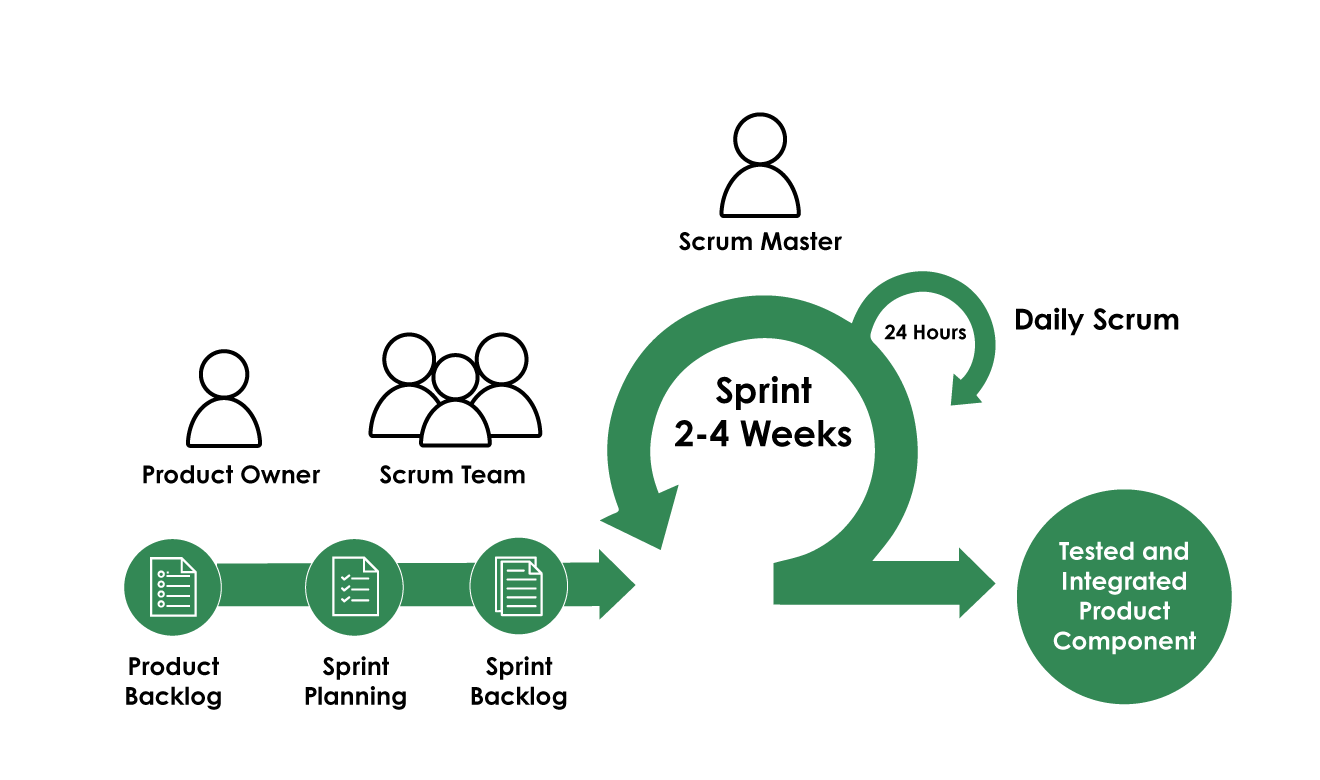
This often manifests as "Zombie Sprints" – iterations where code is shipped, but nothing meaningfully advances the product or platform stability. It looks like progress, but it's motion sickness. We encountered a team "closing" sprints with features technically "done" but utterly unusable due to integration bugs or platform limitations ignored during planning. A McKinsey article touches upon how crucial effective team practices are for velocity, far beyond just adhering to ceremony names. At 1985, our retrospectives are forensic. We use a "5 Whys + RCA (Root Cause Analysis)" approach specifically tailored for distributed teams to uncover process flaws, not just superficial symptoms.
Actionable Takeaway: Use this Sprint Retrospective Checklist for Distributed Teams:
Did we meet the sprint goal (not just close tickets)? Why/Why not?
What was the biggest unexpected technical challenge encountered?
Where did communication falter (internally or with client)? How can we fix it?
Was our estimation accurate? If not, what caused the variance?
(1985 Special) Identify one piece of technical debt incurred this sprint and one piece retired.
Building the 'Minimum Viable Platform' - The 1985 Way
Building a Micro SaaS MVP with an outsourced partner requires a deliberate focus on the platform from day zero. It's not about gold-plating; it's about smart foundations.
Foundational Focus: Infrastructure as Code (IaC) from Day Zero
Your infrastructure shouldn't be a manually configured black box. Use tools like Terraform or Pulumi from the start, even for the simplest MVP setup. This ensures consistency, repeatability, and makes future scaling manageable, not terrifying.
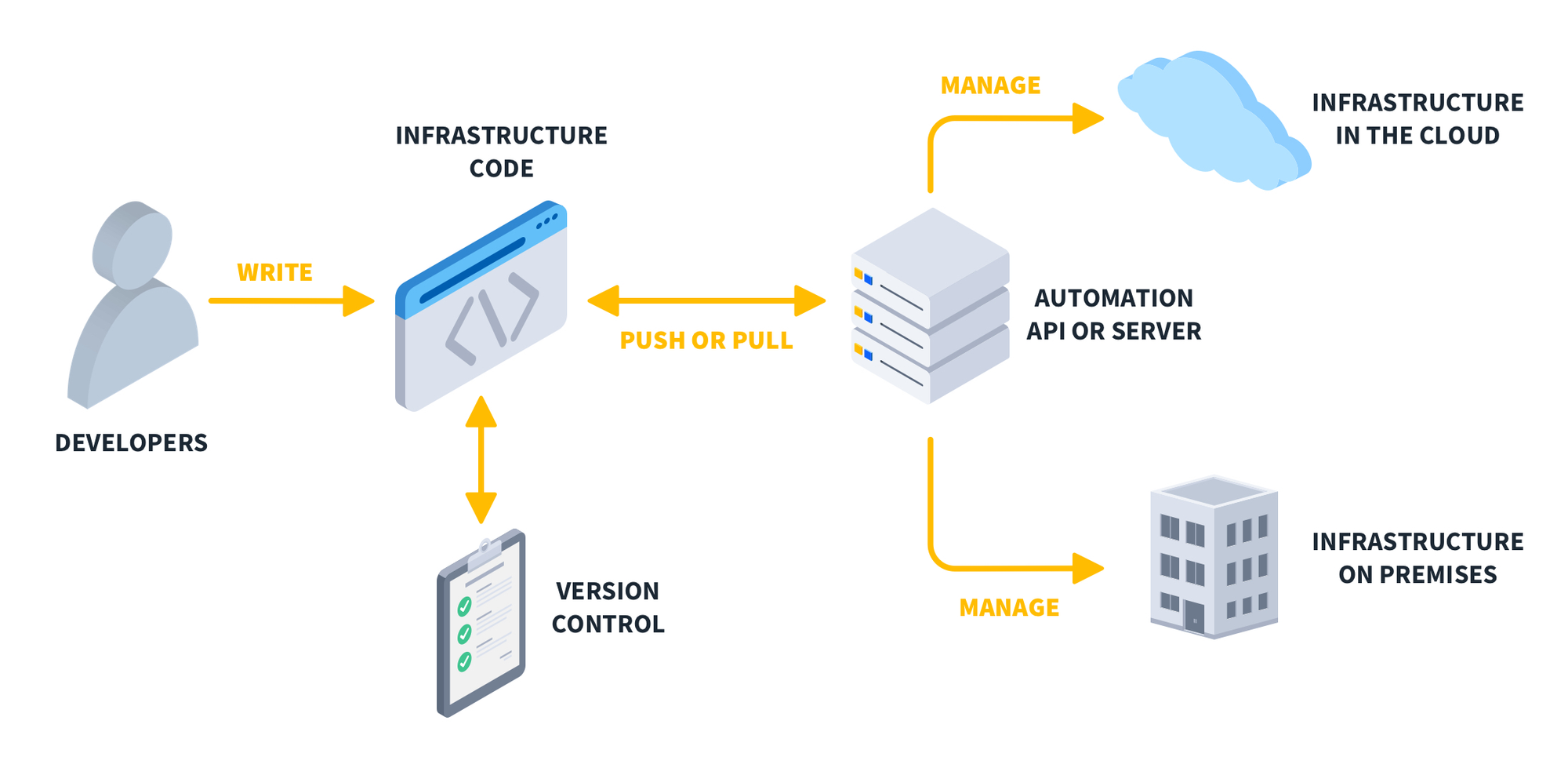
Cloud misconfigurations are rampant and costly. Internal data from 1985's audits consistently shows over 60% of inherited projects lack any IaC, leading to environment drift and security vulnerabilities. One client, pre-1985, faced weeks of downtime trying to replicate their "working" staging environment to production because it was all manual clicks and forgotten settings. Implementing IaC was our first step. It seemed like "overhead" initially, but it paid for itself within two months via predictable deployments and zero environment-related rollbacks. Define your core infra. Code it. Version it.
Actionable Takeaway: Mandate that your MVP hosting setup (even if just a single server/container) be defined using an IaC tool. Check the code into your repository alongside your application code.
Security Isn't an Add-on; It's the Floor
MVPs are frequent targets precisely because security is often deferred. Basic security hygiene isn't optional. It is the minimum viability for anything handling user data or payments. OWASP Top 10 isn't advanced computer science; it's basic blocking and tackling.
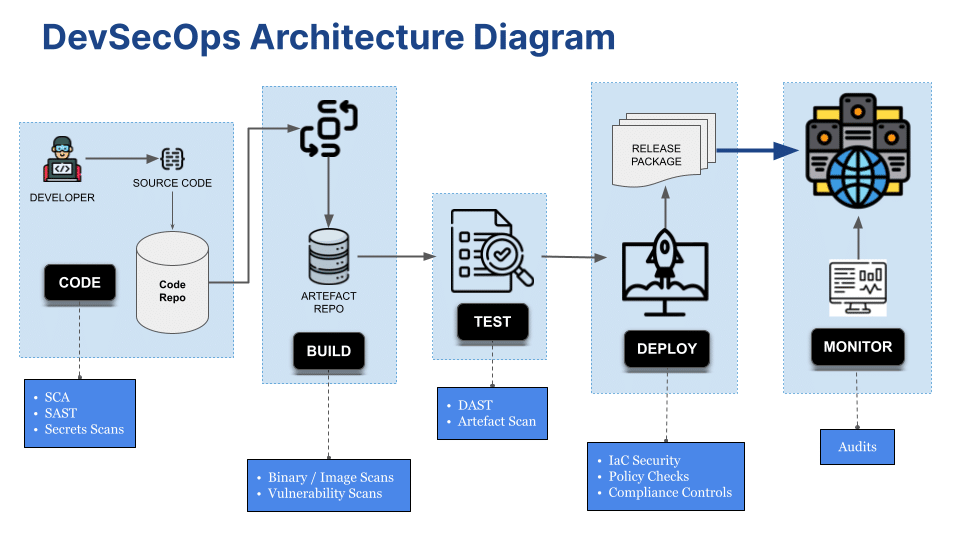
The cost of a data breach, even for a small startup, can be fatal. We were brought into an EdTech platform post-launch after their initial outsourced MVP suffered a breach leaking early user data. The cause? A simple SQL injection vulnerability missed by the previous team's non-existent security review process. Our standard process includes mandatory static code analysis (SAST) and dependency scanning in the CI/CD pipeline, even for MVPs. We catch the low-hanging fruit before it gets deployed. Security starts sprint zero.
Actionable Takeaway: Implement an MVP Security Checklist:
Are dependencies scanned for known vulnerabilities (e.g.,npm audit,pip check)?
Is input validation performed on all user-supplied data?
Are secrets (API keys, passwords) managed securely (e.g., Vault, AWS Secrets Manager), not hardcoded?
Is HTTPS enforced everywhere?
Has basic OWASP Top 10 awareness been discussed with the team?
Observable & Testable: Building for Insight
If you can't measure it, you can't improve it. Or fix it. Your MVP needs basic logging, monitoring, and testing built-in. Without these, you're flying blind. Debugging becomes guesswork, performance issues remain hidden until they cause outages, and feature validation is purely manual.
As the aforementioned Stripe Developer Coefficient report implies, good tooling and visibility boost productivity significantly. We rescued a Micro SaaS where the founder was spending 50% of his time manually checking logs across disparate systems after the outsourced team delivered an "MVP" with zero observability. Implementing basic structured logging (JSON) funnelled into a simple aggregation tool (like a managed ELK stack or Datadog) transformed their debugging process overnight. Add basic health checks and endpoint monitoring. Build for insight.
Actionable Takeaway: Define your MVP Observability Stack early. Minimally:
Logging: Structured logs (JSON) pushed to a central aggregator.
Monitoring: Basic application health checks (uptime, response time for key endpoints). Basic infrastructure metrics (CPU, memory).
Testing: Unit tests for critical business logic. Basic integration tests for core user flows. Aim for quality, not just quantity, of tests.
HealthTech Micro SaaS Turnaround
Let's make this concrete. We engaged with a founder in the HealthTech space. Their initial MVP, built by a freelancer marketplace team, was technically "functional" but operationally a disaster.
The Initial Chaos:
- Deployments took 4-6 hours manually, often failed.
- Frequent data inconsistencies due to poor schema design and lack of transaction management.
- No meaningful logs; debugging involved
sshandgrep. Gross. - Security audit revealed critical PII exposure risks.
- Scaling beyond 50 concurrent users caused performance degradation. The platform wasn't viable.
The 1985 Intervention:
- Stabilize: Immediate implementation of IaC (Terraform) for reproducible environments. Basic CI/CD pipeline established (GitLab CI). Secrets moved to Vault.
- Secure: Addressed critical OWASP vulnerabilities. Implemented automated dependency scanning. Enforced stricter input validation.
- Observe: Integrated structured logging (Serilog) feeding into Datadog. Added basic application performance monitoring (APM).
- Refactor (Targeted): Rewrote the core data persistence layer with proper transaction handling and schema improvements. Introduced unit tests for this critical module. We didn't rewrite everything – just the burning foundation.
Key Lessons & Metrics Post-Engagement:
- Deployment time reduced from ~5 hours to ~15 minutes.
- Critical security vulnerabilities eliminated. Passed subsequent audits.
- Debugging time reduced by an estimated 70% due to proper logging/monitoring.
- Platform stable up to 500 concurrent users with predictable performance.
- The founder could finally focus on features and growth, not firefighting.
As the [Anonymous HealthTech Founder] told us: "Outsourcing felt like gambling until 1985. They didn't just build features; they built the stable ground we needed to actually run the business. The focus on the platform first changed everything."

Your Partner Needs to See the Platform Picture
Building a Micro SaaS MVP is deceptively complex. The 'Minimum' must apply to features, but the 'Viable' absolutely depends on the 'Platform'. Don't let an outsourced partner convince you otherwise to hit an artificial deadline or a lowball quote.
The right partner understands that infrastructure, security, testability, and observability aren't gold-plating; they are the non-negotiable foundation. They build for Day 1 and Day 100. They measure twice, cut once. They prioritize stability because velocity without stability is just organized chaos.
If your current or potential development partner can't clearly articulate their strategy for these 5 platform risks, you need to talk:
- Infrastructure Brittleness: How are environments managed and deployed? (IaC?)
- Security Blindspots: What's the process for secure coding and vulnerability scanning during the MVP build?
- Observability Gaps: How will we monitor and debug the application in production?
- Technical Debt Control: How is tech debt identified, tracked, and addressed within sprints?
- Communication Clarity: How do they ensure shared understanding and resolve ambiguity beyond just assigning tickets?
Building a robust Micro SaaS platform MVP is what we do at 1985. We bring opinionated expertise, battle-tested processes, and a relentless focus on building the right foundation, not just the fast one.
Think your platform MVP strategy might have gaps? Ping us for a no-nonsense platform health check. Let's build something that lasts.


