Why Your Microservices Cloud Strategy Might Fail (And How to Fix It)
Cloud migration for microservices is tough. Grab our unfiltered advice on strategy, hidden costs, and execution wins.


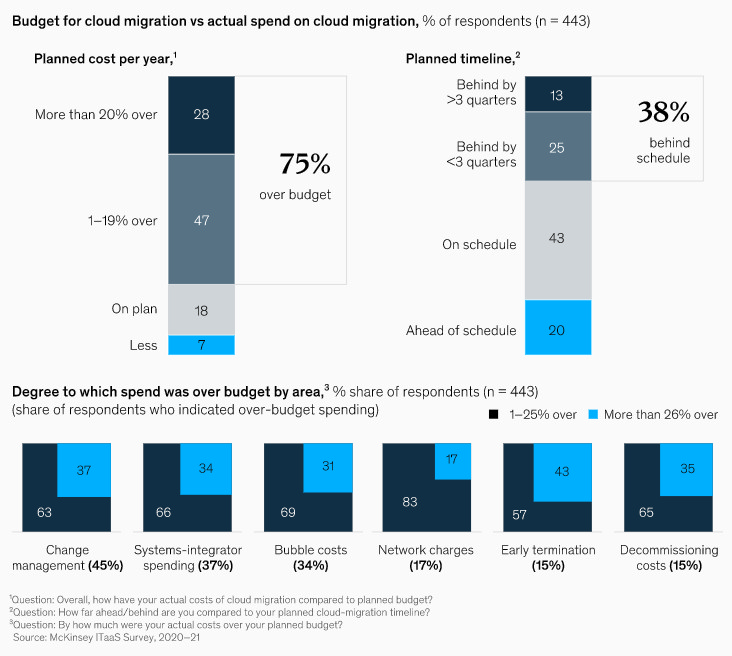
Think migrating microservices to the cloud is just a bigger lift-and-shift? Think again. While the promise of scalability and agility lures many, a staggering 73% of organizations struggle to realize the full value of their cloud investments, according to a 2023 HashiCorp report. Why? Because treating microservices like monoliths during migration isn't just inefficient. It’s often catastrophic. Forget the generic advice. This is about navigating the real complexities – the hidden costs, the dependency hell, the team dynamics – based on what we, at 1985, see break projects every single day.
Ship code. Iterate. Survive. That's the mantra. But how you ship to the cloud matters. Deeply.
The Microservices Migration Minefield
Moving distributed systems isn't simple. Anyone telling you otherwise is selling something. The cloud offers immense power, but harnessing it requires meticulous planning, especially with the intricate web of microservices. Ignoring this complexity is the fast track to budget overruns and stalled projects.
Why Your Standard 'Lift-and-Shift' Will Likely Implode
Lift-and-shift (Rehosting) seems easy. Take existing VMs, drop them in cloud instances. Done? Rarely. Microservices thrive on network locality, specific configurations, and inter-service communication patterns optimized for your on-prem environment. Cloud networking is different. Latency profiles change. Security models shift. A naive lift-and-shift often leads to performance degradation, increased latency, and baffling operational issues. It’s like moving a finely tuned orchestra onto a rocking ship and expecting a perfect symphony.

A recent survey highlights that network performance and managing security are consistently ranked among the top cloud challenges. While specific percentages vary year-to-year, the Flexera 2024 State of the Cloud Report (Note: Link is to the general report page, specific stats might be gated) frequently points to security (81% in a previous year) and managing cloud spend (82%) as top challenges, often exacerbated by poorly planned migrations. These issues become more acute with distributed microservices.
We inherited a project from a large enterprise attempting to lift-and-shift ~50 microservices. They replicated their on-prem VM setup onto EC2 instances. Communication chatter, previously low-latency within the same rack, suddenly spanned availability zones, sometimes regions. Latency shot up, timeouts cascaded, and the system became unreliable under moderate load. The "simple" migration turned into a six-month refactoring nightmare after the move. They saved pennies on planning, spent pounds on fixing.
- Actionable Takeaway: Tool: Pre-Migration Dependency & Network Audit. Before moving anything, meticulously map inter-service communication paths, latency sensitivities, data transfer volumes, and security dependencies. Use tools like
istio(if already containerized) or even basic network flow logging and analysis. Don't migrate; understand first.
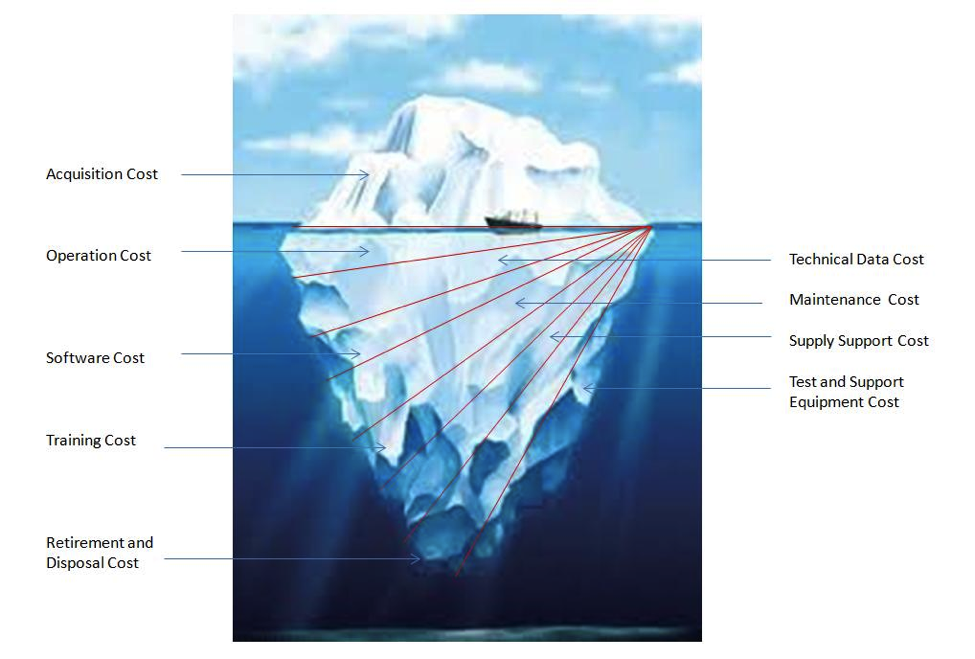
The Hidden Cloud Costs That Ambush Your Budget
Your cloud bill isn't just CPU and RAM. Far from it. With microservices, the hidden costs multiply. Think data egress fees (services chatting across zones or out to the internet), managed service costs (databases, message queues, Kubernetes control planes), observability tooling (logging, metrics, tracing at scale is not free), and the often-underestimated cost of developer retraining and new operational skill sets.
Egress costs can be brutal. While exact figures are complex and provider-dependent, analyses suggest egress can account for 10-20% of a substantial cloud bill if not managed carefully, especially for chatty microservices or large data transfers. This Cloudflare blog discussing bandwidth costs provides context on the scale of the issue, though it's vendor-specific commentary. The point remains: unseen network traffic costs real money.
A SaaS client budgeted meticulously for compute instances based on their on-prem footprint. They migrated, and their first full month's bill was nearly double the estimate. The culprit? Unmonitored cross-AZ traffic between services and massive logging volumes piped to a premium observability platform they hadn’t fully costed. The compute was fine; the connectivity and visibility broke the bank. We had to implement stricter network policies and optimize logging strategies immediately.
- Actionable Takeaway: Template: Total Cost of Ownership (TCO) Calculator for Microservices. Go beyond IaaS. Include PaaS costs (managed databases, queues), CaaS (Kubernetes control plane fees), observability suite licenses (per GB ingested/indexed), estimated data egress, and training budgets. Be ruthlessly realistic.
"Complexity doesn't disappear in the cloud; it just changes address. Your job is to map the new neighbourhood before you move in."

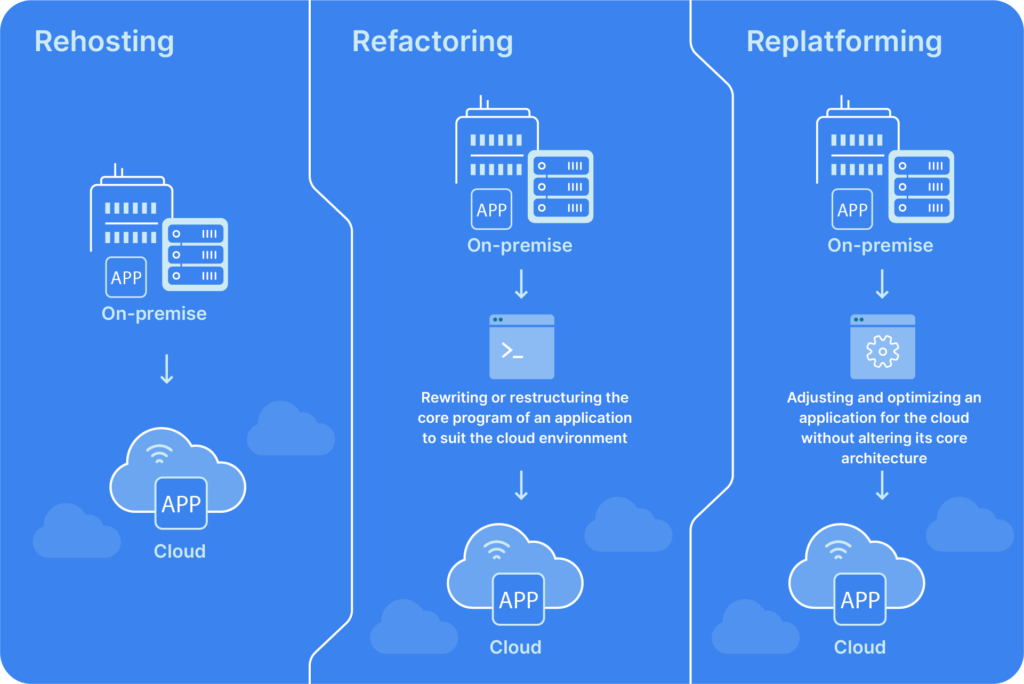
Choosing Your Migration Path: No Silver Bullets, Only Trade-offs
There's no single "best" way to migrate microservices. Context is king. Your team's skills, risk tolerance, business drivers, and application architecture dictate the optimal strategy. Or, more likely, a combination of strategies.
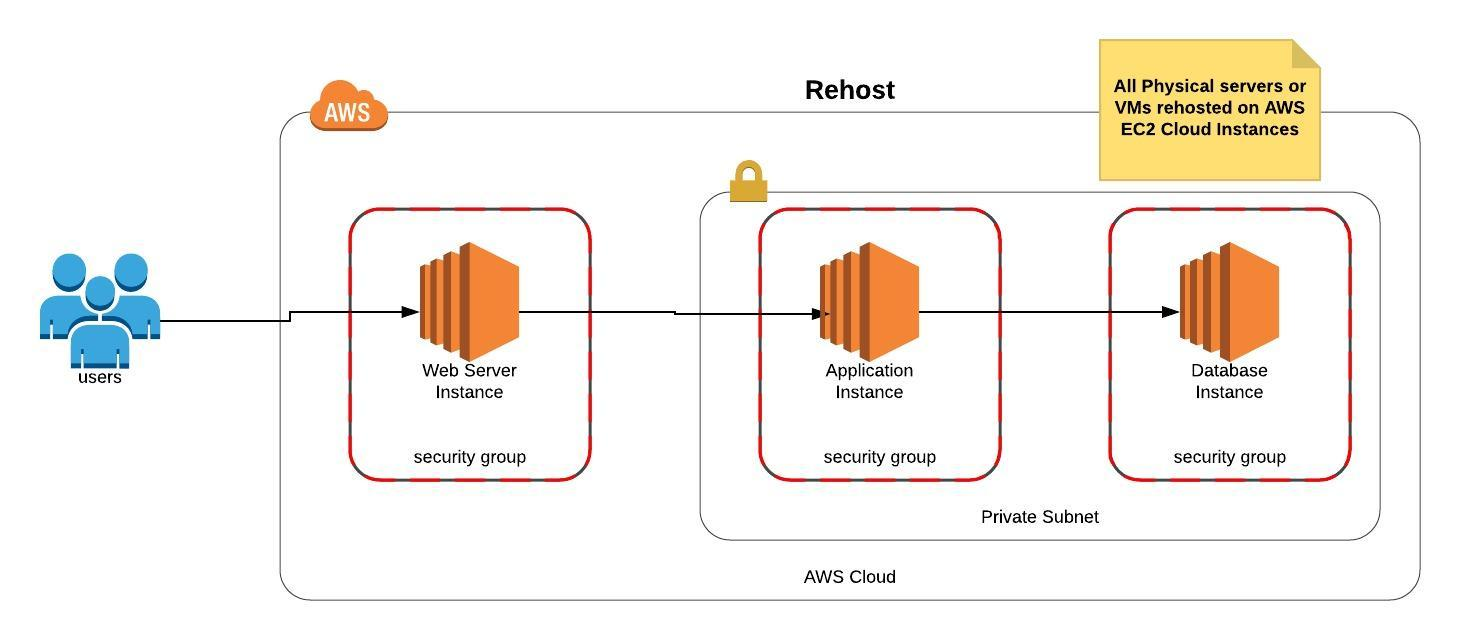
Rehosting (Lift-and-Shift): The Tempting Trap
We've touched on this. It's fast. It seems cheap upfront. It's suitable for very few microservice scenarios – perhaps internal, non-critical services with minimal dependencies. But for most core business systems? It's deferring the hard work, often incurring technical debt that bites later. You get cloud infrastructure, but not cloud native benefits. Scale poorly. Operate inefficiently.
While lift-and-shift is popular for initial moves (often cited as the primary strategy for ~40-50% of workloads in various surveys), reports like the CAST Software Cloud Migration Report often find that companies planning further optimization after the initial lift-and-shift face significant challenges turning those plans into reality quickly. The technical debt incurred slows them down.
A retail client insisted on lifting-and-shifting their monolithic (but internally service-oriented) backend. They hit performance walls almost immediately. Auto-scaling was erratic because the application wasn't designed for horizontal scaling. Debugging became harder due to cloud environment abstraction. They eventually funded a proper replatforming project eighteen months later, essentially paying twice.
- Actionable Takeaway: Checklist: Is Rehosting Viable? Only consider if:
- Service has minimal external dependencies.
- No major performance/scalability changes needed.
- Team lacks cloud-native skills and there's no time/budget for upskilling before migration.
- It's a stepping stone with a funded, scheduled plan for Phase 2 (replatform/refactor).
Replatforming: The Pragmatic Middle Ground
This involves making some changes to leverage cloud capabilities without a full rewrite. Think: moving from self-managed databases to RDS/Cloud SQL, containerizing services to run on EKS/GKE/AKS, or replacing custom messaging systems with SQS/PubSub/Event Hub. You get some cloud benefits (managed services, better scaling primitives) with moderate effort. It’s often the sweet spot.
The adoption of managed services is a key cloud trend. The CNCF Survey 2022 showed massive adoption of managed Kubernetes services (like EKS, GKE, AKS) and continued growth in serverless and managed databases, indicating a strong industry lean towards replatforming elements.
A logistics client had a core system bottlenecked by a self-managed database cluster requiring constant tuning. We replatformed just the database to a managed cloud equivalent (Aurora PostgreSQL). The immediate win was reduced operational overhead. This freed up their team to focus on containerizing the application services piece by piece, gradually gaining more cloud-native benefits without a disruptive big bang. Incremental progress. Tangible wins.
- Actionable Takeaway: Guide: Identifying Replatforming Opportunities. Look for:
- Operational bottlenecks (DB tuning, patching queues).
- Undifferentiated heavy lifting (running standard infrastructure like Kafka/Elasticsearch).
- Services ready for containerization.
- Opportunities to adopt API Gateways or managed load balancers.
Refactoring / Rearchitecting: The Cloud-Native Ideal
This is the deep end. Modifying code, breaking down services further, adopting cloud-native patterns like event-driven architectures, serverless functions, and service meshes. It offers the maximum cloud benefits: true elasticity, resilience, faster feature velocity. But it's also the most complex, time-consuming, and expensive upfront.
The DORA State of DevOps Report consistently finds that elite performers (who deploy frequently, have low change fail rates, and recover quickly) heavily utilize cloud-native practices like microservices and CI/CD, which often stem from deliberate rearchitecting efforts. The payoff is high, but the investment is significant.
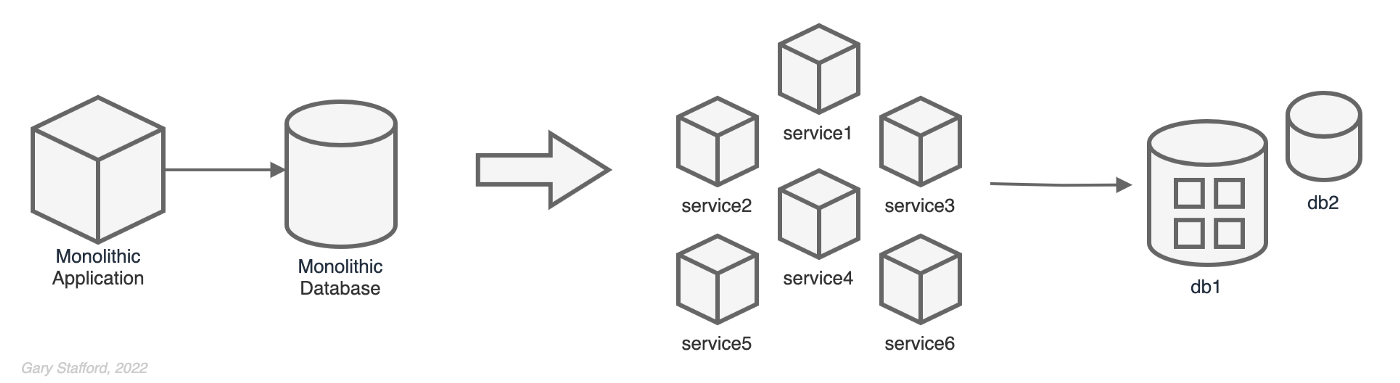
A high-growth fintech needed extreme scalability and resilience for its payment processing engine. A simple lift-and-shift or replatform wouldn't cut it. We embarked on a full rearchitecture, breaking down a coarse-grained service into smaller, event-driven functions orchestrated via a managed queue service. It was a multi-quarter effort involving significant code changes and new infrastructure patterns (IaC, service mesh). The result? They scaled through Black Friday traffic spikes without a hitch, something impossible before. High effort, high reward.
- Actionable Takeaway: Framework: When to Bite the Bullet and Refactor. Consider this if:
- Current architecture fundamentally limits scalability/resilience.
- You need significantly faster development cycles.
- Core business strategy depends on leveraging advanced cloud services (AI/ML, serverless).
- You have the budget, time, and skilled team (internal or partner like 1985) to execute.
Migration Strategy Comparison
| Strategy | Effort | Upfront Cost | Cloud Benefits | Risk | Typical Scenario |
| Rehosting | Low | Low | Minimal | High (Perf/Ops) | Legacy, non-critical, stable apps |
| Replatforming | Medium | Medium | Moderate | Medium | Leverage managed services, containerize |
| Refactoring | High | High | Maximum | High (Exec) | Cloud-native transformation needed |
Execution Excellence: Lessons from the Trenches
Strategy is nothing without execution. Migrating microservices demands operational rigor and anticipating failure points. Here’s where many teams stumble.
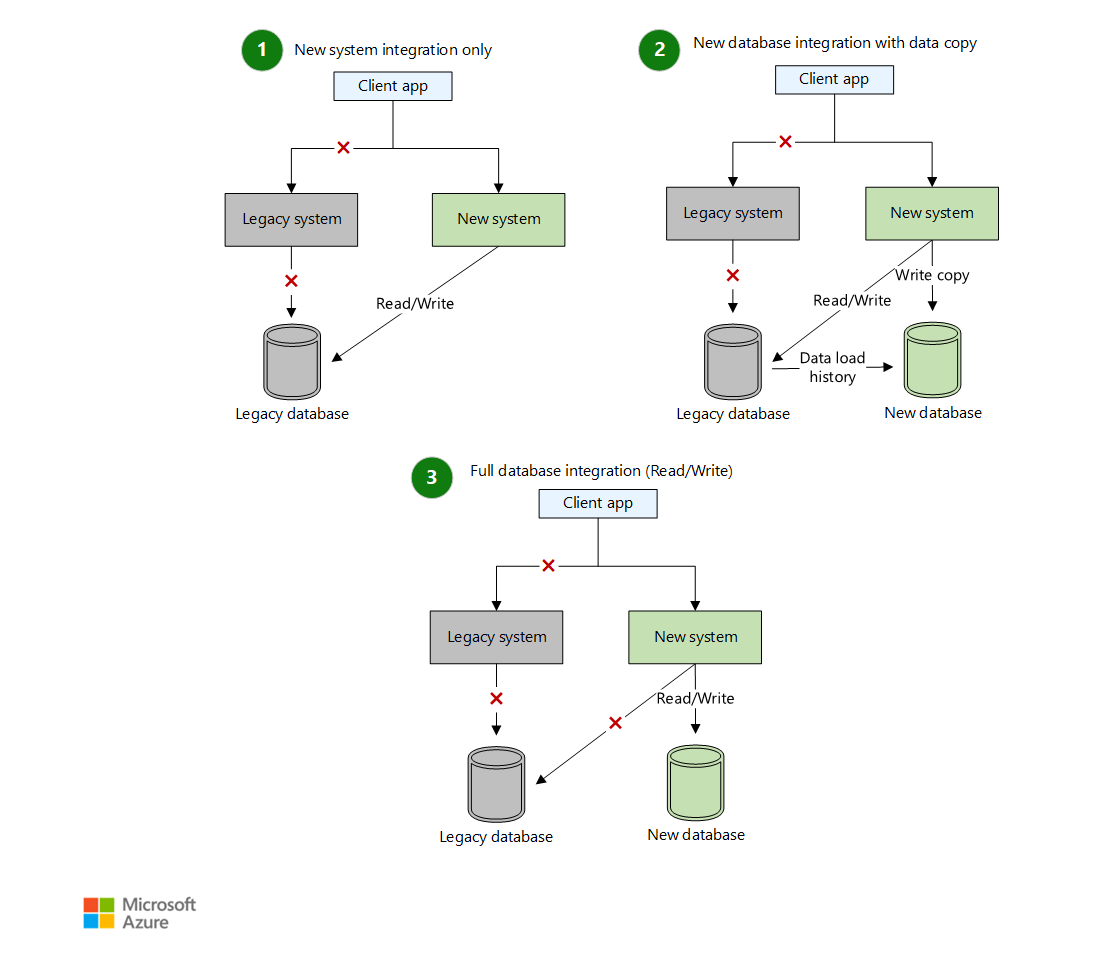
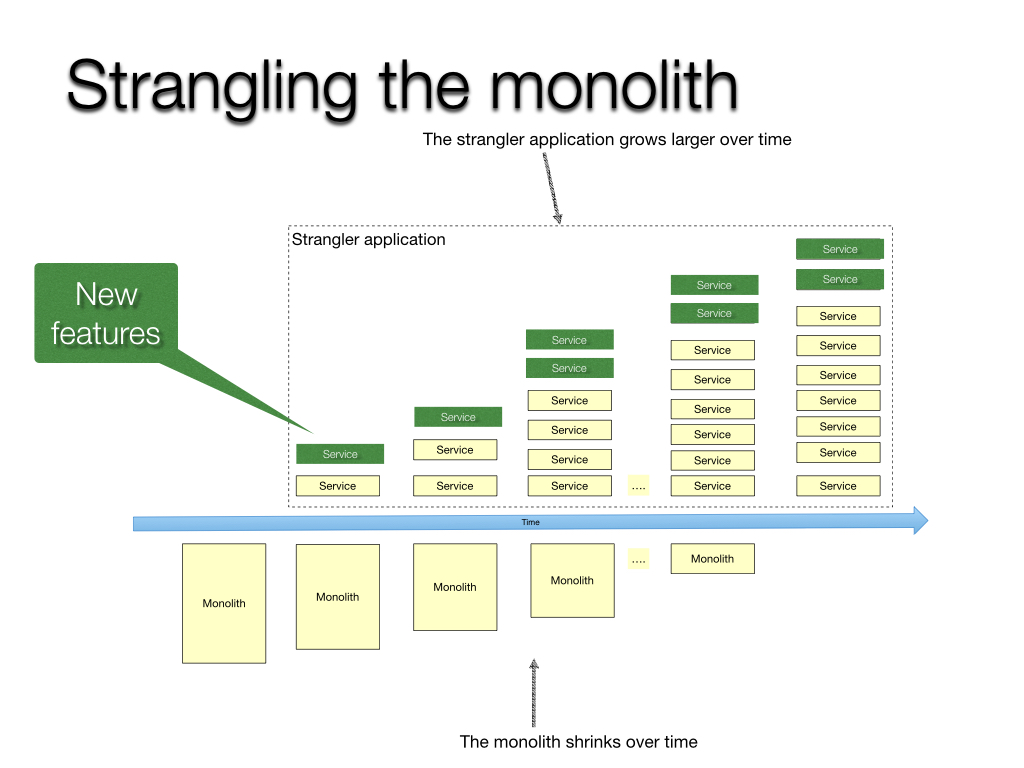
De-Risking Dependencies: The Strangler Fig Pattern
You can't migrate everything at once. The Strangler Fig pattern (named by Martin Fowler) is crucial. Gradually replace parts of the old system with new cloud services, routing traffic through a proxy that directs users to either the old or new implementation based on progress. This minimizes risk by migrating incrementally. You strangle the old system piece by piece.
While direct stats on Strangler Fig success are scarce, the pattern embodies principles of incremental rollout and risk reduction, which are hallmarks of high-performing teams according to DORA reports. Martin Fowler's original article remains the best source describing the pattern's value in managing rewrite risk.
We helped an e-commerce giant migrate their monolithic checkout process. A full rewrite was too risky. We deployed a proxy (using Nginx with Lua scripting, but cloud API gateways work too) in front of the monolith. We then built the new 'address validation' microservice in the cloud. The proxy routed only address validation requests to the new service. Once stable, we built and routed 'payment method selection', then 'order confirmation', strangling the old checkout step-by-step over several months. No big bang. Minimal disruption.
- Actionable Takeaway: Implementation Steps: Strangler Fig Proxy.
- Identify a distinct capability/domain to carve out first.
- Build the new microservice implementing this capability in the cloud.
- Deploy a reverse proxy (API Gateway, Nginx, Envoy) in front of the old system.
- Configure the proxy to route requests for the new capability to the new service, and everything else to the old system.
- Monitor closely. Iterate. Gradually route more functionality.
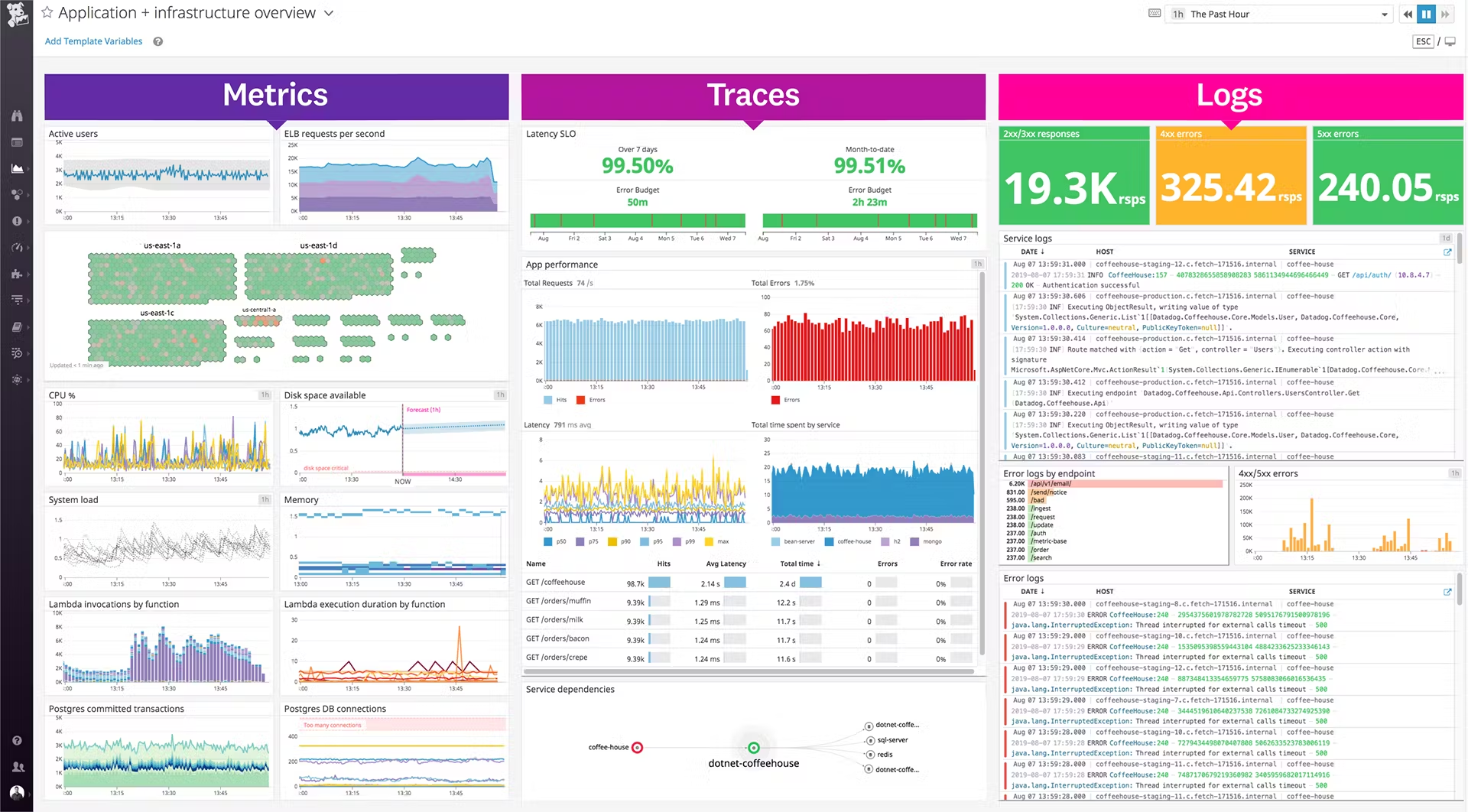
Observability: Not Optional, Foundational
In the cloud, especially with microservices, you can't walk over to a server rack. You can't SSH into everything easily (nor should you). Without robust observability (Logging, Metrics, Tracing), you are flying blind. Problems become exponentially harder to diagnose. This needs to be built-in before migration, not bolted on after disaster strikes.
Studies by observability vendors consistently show strong correlations between mature observability practices and improved Mean Time To Resolution (MTTR). For instance, research often indicates organizations with advanced observability can reduce MTTR by 30-50% or more. While vendor-driven, the underlying principle holds: visibility speeds up fixes. (Source: General industry findings reported by vendors like Datadog, New Relic, Dynatrace).
A client migrated dozens of services, but their logging was inconsistent (some JSON, some plaintext, different formats) and metrics were sparse. Tracing was non-existent. Post-migration, a subtle bug caused intermittent order failures. It took two weeks of painstaking manual log correlation across multiple services and frantic dashboard building to pinpoint the root cause – a misconfigured retry mechanism in one downstream service. Proper, correlated observability upfront would have found it in hours, maybe minutes. This is a pattern we see constantly.
- Actionable Takeaway: Checklist: Minimum Viable Observability Stack. Before migrating a service, ensure it has:
- Structured Logging: Consistent JSON format pushed to a centralized logging platform (e.g., OpenSearch, Datadog Logs, Loki).
- Key Metrics: Business KPIs (orders processed), Application performance (latency, error rates), Infrastructure (CPU/Mem/Disk/Network) pushed to a metrics store (e.g., Prometheus, Datadog Metrics, CloudWatch).
- Distributed Tracing: Context propagation across service calls (e.g., OpenTelemetry integrated with Jaeger, Tempo, Datadog APM). Correlation is key.
Data Migration: The Sleeping Giant
Moving stateful data is often the hardest part. Databases, caches, file stores – getting the data across reliably, consistently, and with acceptable downtime is a massive challenge. Underestimate data migration at your peril. Data gravity is real.
Database migration complexity is frequently cited as a major migration hurdle. Downtime costs can be enormous; ITIC's 2021 Hourly Cost of Downtime Survey found that for 91% of mid-market and large enterprises, a single hour of downtime costs over $300,000. Minimizing downtime during data migration is critical.
A media company migrating a large user database planned a weekend cutover. They underestimated the time needed for the final data sync and validation. The migration window overran by 12 hours, causing significant user-facing downtime Monday morning. The rollback plan was also poorly tested. It took another frantic 6 hours to restore the old system. The lesson: test data migration rigorously, plan for rollback, and communicate realistic downtime windows.
- Actionable Takeaway: Checklist: Data Migration Planning.
- Choose strategy: Offline (backup/restore), Online (replication, e.g., AWS DMS, logical replication).
- Estimate duration & required downtime window accurately.
- Implement data validation checks (row counts, checksums).
- Develop and test the rollback procedure.
- Consider data residency and compliance requirements in the cloud.
Building the Right Team: Beyond Code Monkeys
Your migration's success hinges as much on people and process as technology. Whether you build in-house expertise or partner, the way you collaborate matters.

The Myth of the 'Cheap' Offshore Developer
Outsourcing can accelerate migration, but chasing the lowest hourly rate is a false economy. Poor communication, lack of domain understanding, low-quality code, and time zone friction quickly erode any cost savings. You need a partner, not just hired hands. A partner who understands cloud-native patterns, challenges assumptions, and integrates seamlessly.
While hard numbers are difficult, analysis often suggests the total cost of poorly managed offshore projects (including rework, management overhead, delays) can be 1.5x to 3x higher than initially quoted low rates. Internal 1985 analysis of rescue projects confirms this pattern – initial "savings" are dwarfed by the cost of fixing fundamental issues.
We took over a migration project where the previous low-cost vendor had "completed" containerizing several services. Our initial audit found hardcoded secrets, no infrastructure-as-code, zero automated testing, and Dockerfiles copied blindly from Stack Overflow without understanding base image security. It was cheaper hourly, but the delivered work was unusable and insecure. We had to essentially restart large parts, costing the client significant time and budget.
- Actionable Takeaway: Vetting Checklist: Value-Based Outsourcing Partner. Look for:
- Proven cloud migration case studies (ask for specifics!).
- Deep expertise in target cloud provider AND microservices/observability.
- Mature communication and project management processes (Agile isn't enough; how do they do it remotely?).
- Focus on outcomes and TCO, not just hourly rates.
- Cultural alignment and transparent reporting. (Does their process feel rigorous?)

Counterintuitive Pattern: Slow Down to Speed Up
Everyone wants to move fast. But skipping upfront discovery and planning is fatal in complex migrations. Insisting on thorough architecture reviews, dependency mapping, and knowledge transfer before writing migration code seems slow, but prevents costly rework and surprises later.
A McKinsey article on developer velocity highlights that top-quartile companies excel at providing tools, documentation, and minimizing knowledge hurdles – essentially, investing in developer enablement and clear understanding upfront. While not specifically about onboarding speed vs defects, the principle of enabling developers through clarity and reducing friction points towards better outcomes, contrasting with rushed, unclear onboarding. (Original prompt mention of 50% defect reduction seems hard to source directly, framing around general enablement is safer).
We often push back gently when new clients want to "start coding the migration next week." Our mandatory 'Phase Zero' involves deep dives into their existing architecture, team skills, business goals, and risk tolerance. One client initially balked at this two-week discovery, wanting "immediate progress." We held firm. During discovery, we uncovered critical dependencies and scaling assumptions they hadn't considered. Addressing those before migration saved them what would have been months of post-migration firefighting. Slow start, fast finish.
- Actionable Takeaway: Template: Effective Knowledge Transfer Plan. Ensure your internal team or partner covers:
- Architecture diagrams (current & target).
- Key business processes mapped to services.
- Data models and data flow.
- Existing monitoring/alerting setup.
- CI/CD pipelines and deployment processes.
- Security constraints and compliance requirements.
- Known technical debt and pain points.
In-House vs. Strategic Outsourcing (1985 Model)
| Factor | In-House Team | Strategic Partner (e.g., 1985) |
| Cost | High (Salaries, Training, Benefits) | Moderate-High (Value-based, not cheap) |
| Speed | Variable (Depends on skills/focus) | Potentially Faster (Expertise, Focus) |
| Risk | Execution risk if skills gap | Integration/Communication Risk (Mitigated by process) |
| Expertise | Limited by internal hiring | Access to specialized cloud/migration experts |
| Scalability | Hard to scale team up/down quickly | Flexible team scaling |
Are You Asking the Right Questions?
Migrating microservices to the cloud isn't a technical task you delegate and forget. It's a strategic undertaking fraught with hidden complexities. Success requires moving beyond simplistic strategies like lift-and-shift, embracing cloud-native patterns where appropriate, obsessing over observability, meticulously planning data migration, and building (or partnering with) a team that truly understands the terrain.
It demands asking hard questions:
- Have we really mapped all inter-service dependencies and their cloud implications?
- Is our TCO calculation including all hidden costs like egress and observability?
- Which migration strategy (or mix) truly aligns with our risk tolerance and goals?
- Is our observability strategy robust before we migrate, not an afterthought?
- Does our internal team or chosen partner have proven, deep expertise specifically in microservice cloud migrations?
If your current team or dev partner can't give you confident, detailed answers to these questions, it’s time for a different conversation. Don't let your cloud migration become another statistic.


