When AI Agents Stop Talking
When AI agents stop talking, systems fail. Learn how to build resilient multi-agent systems that communicate flawlessly.


Building reliable multi-agent systems isn’t just a technical challenge. It’s a test of foresight, design, and resilience. When agents stop talking, things can unravel quickly. And if you’ve ever had a distributed system fail silently, you know the cost can be more than just a frustrated engineering team. It can be lost revenue, degraded customer experiences, and even reputation damage.
This guide is for engineers, architects, and product leaders who care about building robust AI-driven systems. We’re going beyond the basics. No “What is an AI agent?” here. Instead, we’ll explore the intricate mechanics of communication protocols, error handling, and reliability strategies. Let’s dive into what really matters.
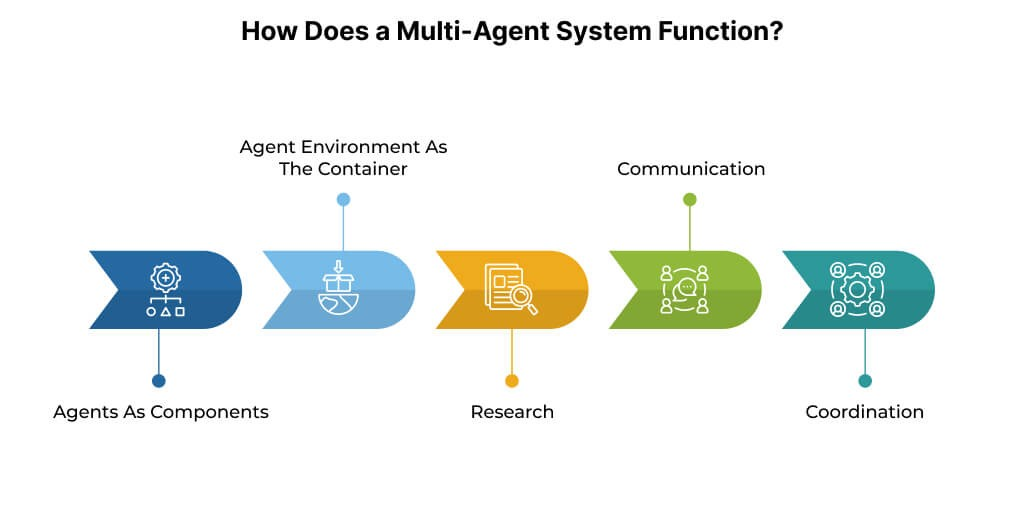
Why Multi-Agent Systems Break
Before fixing a problem, you need to understand why it happens. Multi-agent systems fail for several reasons, and communication issues often top the list. Here are some common culprits:
- Network Latency and Packet Loss: Agents rely on networks to communicate. Even small latencies can disrupt tightly synchronized processes. Packet loss? That’s a whole new layer of chaos.
- Unclear Protocols: If your agents don’t speak the same language, expect misunderstandings. Protocol mismatches lead to dropped messages or worse—misinterpreted actions.
- State Drift: Agents often maintain internal states. When states go out of sync, they make poor decisions. Worse, they might not realize they’re out of sync.
- Error Propagation: A single failure can cascade. One agent crashes, another waits for input, and suddenly your whole system is stuck in a deadlock.
- Over-Reliance on Central Nodes: Many systems depend on a central orchestrator. If it falters, the entire network collapses.
Real-World Example
In 2017, a major cloud provider experienced a 4-hour outage due to an agent miscommunication issue. An AI model used for load balancing made incorrect predictions due to outdated state information, leading to a cascading failure. It wasn’t just a technical glitch; it caused millions in losses for clients relying on their services.

Designing Communication Protocols
Effective communication is the backbone of any multi-agent system. Here’s how to get it right.
1. Standardize Message Formats
Agents need a common language. This can be achieved using protocols like:
- JSON-RPC: Simple and human-readable.
- Protobuf: Compact and efficient for large-scale systems.
- gRPC: Built on HTTP/2, it’s ideal for low-latency requirements.
A standardized schema ensures everyone speaks the same dialect. Tools like OpenAPI or Protocol Buffers Schema Registry help enforce this.
2. Implement Heartbeats
Heartbeats are periodic signals sent by agents to indicate they’re alive. They’re invaluable for:
- Detecting unresponsive agents.
- Preventing resource wastage on dead nodes.
- Ensuring synchronization.
But keep the intervals sensible. Too frequent, and you’ll choke the network. Too sparse, and failures go unnoticed.
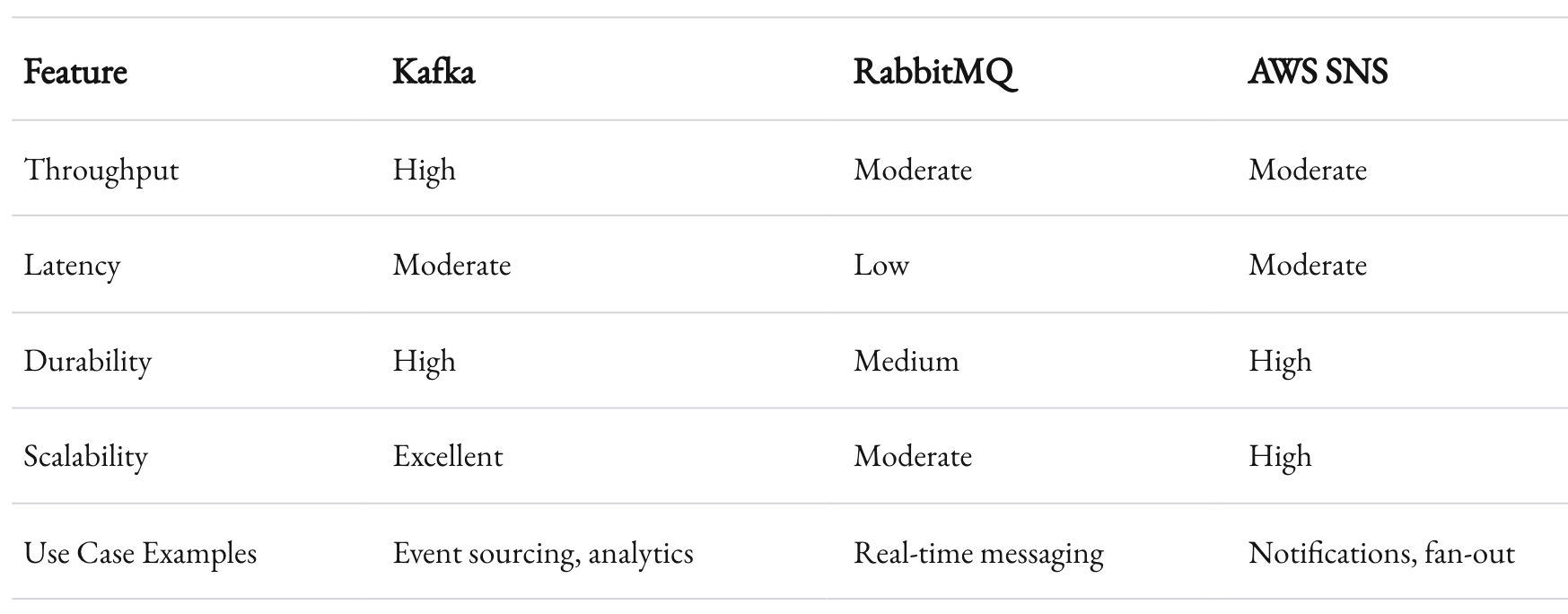
3. Use Publish-Subscribe Models
The pub-sub pattern decouples agents. Instead of direct communication, agents publish messages to topics, and others subscribe to relevant ones. This reduces dependencies and enhances scalability. Popular tools include:
- Kafka: High throughput and durability.
- RabbitMQ: Flexible routing and low latency.
Here’s a table comparing the two:

Handling Failures Gracefully
Failures are inevitable. Your system’s resilience depends on how well you’ve planned for them.

1. Retry Mechanisms
When a message fails, retry. But don’t retry blindly. Use exponential backoff to avoid overwhelming the system. A typical retry strategy looks like this:
- Initial attempt.
- Wait 1 second; retry.
- Wait 2 seconds; retry.
- Wait 4 seconds; retry.
This approach balances urgency with system stability.
2. Circuit Breakers
A circuit breaker prevents overloading. When an agent detects repeated failures, it stops trying temporarily. This gives systems time to recover. Libraries like Netflix’s Hystrix or Resilience4j make implementation straightforward.
3. Quorum-Based Decisions
In critical scenarios, don’t rely on a single agent’s input. Use quorum-based voting. For example, in a 5-agent system, require at least 3 to agree before proceeding. This reduces the risk of a single point of failure.
Case Study
A logistics company using AI agents for route optimization faced intermittent failures due to unstable network connections. By implementing retries with exponential backoff and circuit breakers, they reduced error rates by 60%. Adding quorum-based decisions further minimized incorrect route assignments.

Synchronizing State
State synchronization is a subtle yet critical aspect of multi-agent systems.
1. State Replication
Use replication to ensure all agents have the same state. Tools like Apache ZooKeeper or Consul are popular choices. They maintain a central repository for state data, accessible by all agents.
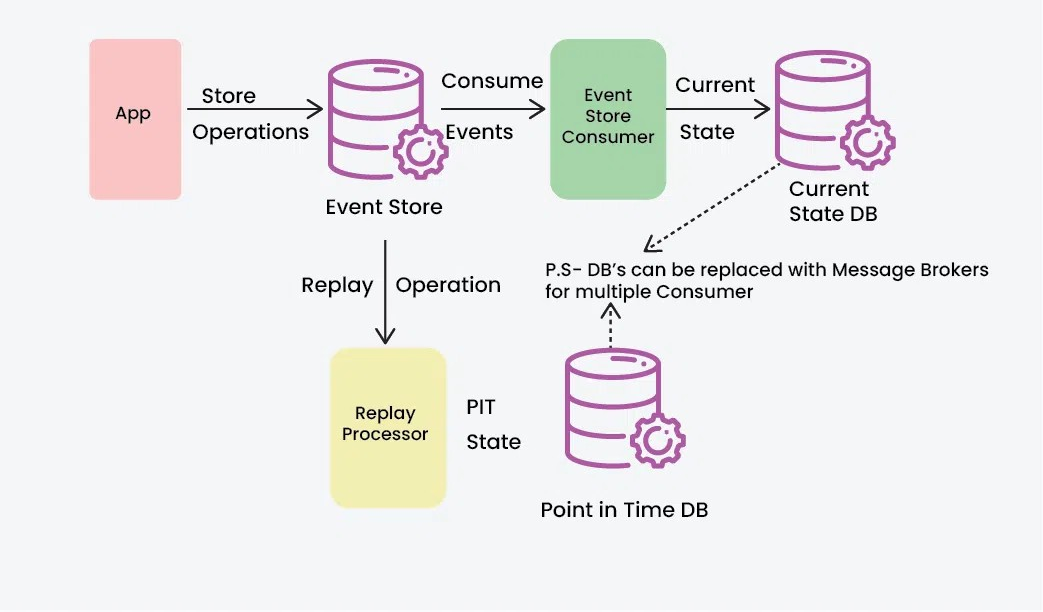
2. Event Sourcing
Instead of saving the current state, save the events that led to it. This makes reconstructing state easier. Frameworks like Akka and EventStore simplify this process.
3. Conflict Resolution
When states diverge, conflicts arise. Strategies to resolve them include:
- Last Write Wins (LWW): Prioritize the latest update.
- Merge Strategies: Combine conflicting data intelligently.
For instance, in a bidding system, conflicting bids might be merged by choosing the higher one.

Testing Multi-Agent Systems
Testing multi-agent systems is notoriously complex. Traditional unit tests don’t cut it. Here’s how to approach it.
1. Simulated Environments
Create a sandbox where agents can interact. Simulators like MATSim for transport systems or OpenAI Gym for reinforcement learning help replicate real-world scenarios.
2. Chaos Testing
Popularized by Netflix, chaos testing involves intentionally breaking things. Use tools like Chaos Monkey to:
- Terminate random agents.
- Simulate network outages.
- Introduce latency.
These tests expose weaknesses before they occur in production.
3. End-to-End Testing
Mock environments are useful, but real-world data is king. Use staging environments with production-like traffic to validate performance.
Moving Beyond Technical Challenges
Technology is only part of the equation. Building reliable systems requires strong collaboration between teams. Regular cross-functional reviews, clear documentation, and shared ownership are essential.
At 1985, we’ve learned this the hard way. While working on a multi-agent logistics platform, early miscommunication between our dev and ops teams led to a month-long delay. Once we introduced bi-weekly alignment meetings and standardized our documentation practices, the issues cleared up. The result? A system that’s now handling millions of transactions daily without a hitch.
Recap
Multi-agent systems are powerful but fragile. When agents stop talking, everything grinds to a halt. By focusing on communication protocols, robust error handling, and resilient design patterns, you can build systems that thrive in the real world.
But remember, technology is only as strong as the people behind it. Invest in your teams, iterate relentlessly, and never stop learning. Because when your systems work seamlessly, it’s not just code running efficiently. It’s your vision coming to life.


