Think Cloud-Native is Your Only Path Forward? You Might Be Bleeding Cash.
Think cloud is always cheaper? We explore hidden costs & smart reasons why on-prem still rocks for some businesses.


Let's cut the noise. The endless cycle of "cloud-first" evangelism often ignores a harsh reality. While cloud adoption continues its relentless climb, a surprising number of businesses are grappling with runaway costs and operational chaos. A recent Flexera Cloud Report found that optimizing existing cloud spend remains the top challenge for organizations, with respondents estimating 28% of their cloud spend is wasted. Twenty-eight percent. Wasted.
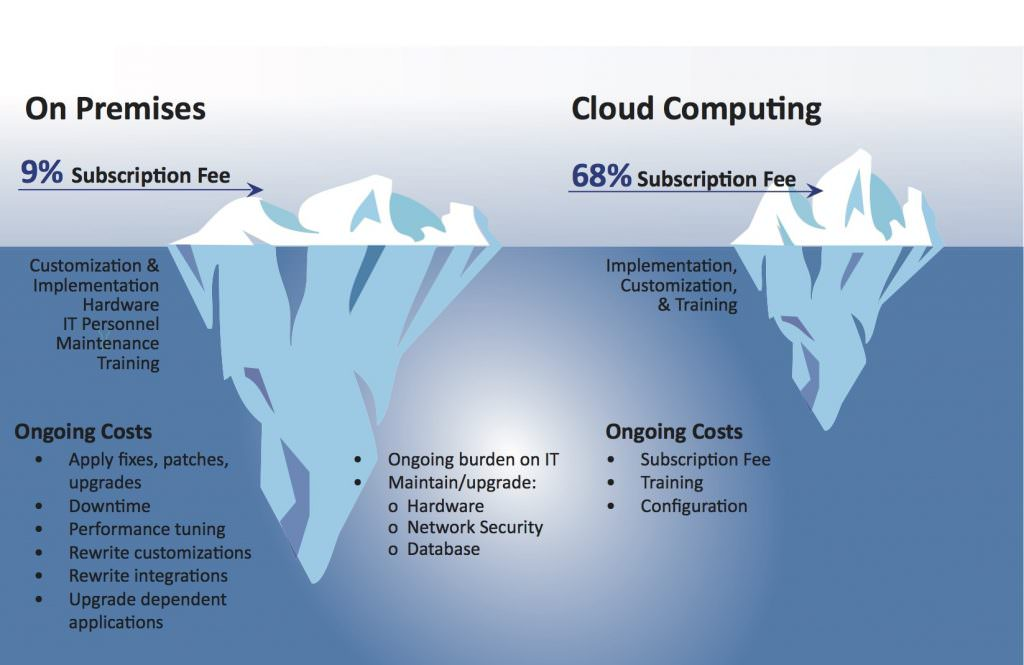
The on-prem versus cloud-native debate isn't binary. It's not a simple choice between legacy shackles and hyper-scaler freedom. It's a strategic decision deeply intertwined with your business model, risk tolerance, regulatory landscape, and—critically—your team's actual capabilities. Forget the generic pros and cons lists. We're diving deeper. We’re talking about the hidden costs, the talent wars, and the pragmatic realities we see daily in the trenches at 1985. This isn't about picking a side. It's about picking right for your specific context.
The Siren Song of Infinite Scale (And the Hidden Icebergs)
Cloud-native promises agility. Elasticity. Pay-as-you-go nirvana. Ship code faster. Iterate constantly. Survive. But the allure often obscures significant operational and financial complexities that can cripple unprepared teams. Moving fast is good. Moving fast into a wall of unexpected costs is not.
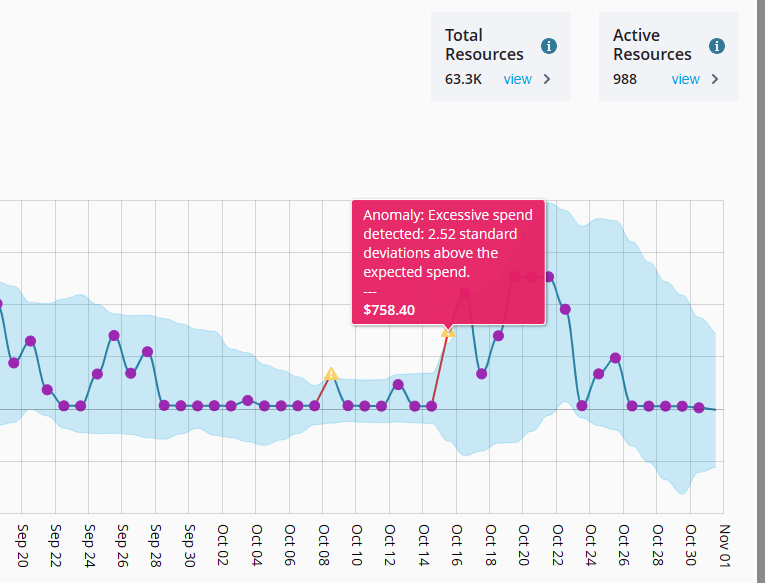
Beyond Compute: The Real Cloud Bill Shock
The sticker price for compute instances or serverless functions is just the beginning. The real costs hide in the margins: data egress fees, inter-zone traffic, managed service premiums, observability tooling, and the sheer engineering hours spent navigating complex cloud provider ecosystems. We had a scale-up client—a promising SaaS platform—nearly stall post-migration. Their dev team, sharp on application logic, drastically underestimated the cost implications of their cross-regional data replication strategy. Egress fees ballooned by 300% month-over-month. It wasn't incompetence; it was a blind spot born from focusing purely on features, not foundational cost architecture. Their initial TCO model? Useless.
This isn't rare. Gartner predicts that through 2025, 90% of organizations that fail to control public cloud use will overspend their budgets. The ease of swiping a credit card for a new service masks the long-term financial implications. Building cloud-native doesn't automatically mean building cost-efficiently. It requires rigorous financial discipline and architectural foresight.
Actionable Takeaway: Implement a FinOps culture early. Don’t treat cloud cost management as an afterthought. Use tools like Cloudability, Kubecost (for Kubernetes), or native cloud provider cost explorers religiously. Mandate cost tagging for all resources from day one.
The Cloud Skills Gap is Real, and It Hurts
Finding competent cloud engineers—especially those proficient in Kubernetes, serverless architectures, and specific managed services—is a battlefield. The demand far outstrips supply. While cloud providers offer certifications, true expertise comes from hands-on experience navigating failures, scaling events, and complex integrations. A 2023 report by Pluralsight highlighted that 75% of technologists felt the skills gap was widening, particularly in cloud computing and cybersecurity.

We worked with a mid-sized e-commerce company eager to go "all-in" on Kubernetes. They hired an external consultant who built a sophisticated cluster. Beautiful architecture. One problem: their internal team lacked the operational chops to manage it effectively post-handover. Minor issues cascaded into outages because debugging distributed systems requires a different skillset than managing monolithic apps on VMs. They were sold a Ferrari but only knew how to drive a sedan. The result? Frustration, slow incident resolution, and eventually, a costly engagement with us at 1985 to provide managed K8s expertise until their team could be upskilled. Don't overestimate your team's bandwidth or ability to instantly pivot to new, complex paradigms.
Actionable Takeaway: Perform an honest skills assessment before committing to a specific cloud-native stack. Invest heavily in training or partner with experts who can bridge the gap. Consider managed services strategically, but understand their cost and lock-in implications. Tool: Use a simple Skills Matrix comparing current team capabilities against the target cloud architecture's requirements.
On-Prem: Not Dead, Just Deliberate
Dismissing on-premises infrastructure as archaic is a strategic error, particularly for businesses with specific regulatory, performance, or cost predictability needs. It’s not about clinging to the past; it’s about leveraging control when control is paramount. Sometimes, the old ways are the right ways.
When Compliance Dictates Location
For industries like finance, healthcare, or government contracting, data sovereignty and strict regulatory compliance (like GDPR, HIPAA, PCI-DSS) aren't negotiable. While cloud providers offer compliant regions and services, demonstrating and auditing that compliance can be complex and costly. Sometimes, keeping sensitive data within your own physical walls is the simplest, most defensible posture. As an unnamed CISO at a European FinTech told us during a security audit: "For our core transaction processing, the regulator prefers seeing it on hardware we physically control. It simplifies the audit trail immensely."
We encountered this with a HealthTech startup handling sensitive patient records. The potential fines for a data breach under HIPAA were existential. While a cloud solution was technically possible, the legal and operational overhead of ensuring and proving HIPAA compliance across a complex chain of cloud services tilted the balance. They opted for a hybrid approach: core patient data resided on hardened, audited on-prem servers, while less sensitive workloads (like their marketing site and analytics sandbox) ran in the cloud. This wasn't a technology limitation; it was a risk management decision.
Actionable Takeaway: Engage your legal and compliance teams early in infrastructure decisions. Don't assume cloud providers' compliance certifications absolve you of responsibility. Map data flows and residency requirements meticulously.
The Predictability Factor: Taming Variable Costs
Cloud costs are notoriously variable. On-premises infrastructure, while requiring significant upfront CapEx, offers predictable OpEx once hardware is purchased and amortized. For workloads with high, stable resource consumption (e.g., large-scale data processing, rendering farms, certain types of ML training), the TCO of running on-prem over 3-5 years can be significantly lower than paying variable cloud rates. The key is utilization. Empty servers are expensive. Fully utilized ones can be bargains compared to equivalent cloud resources running 24/7.
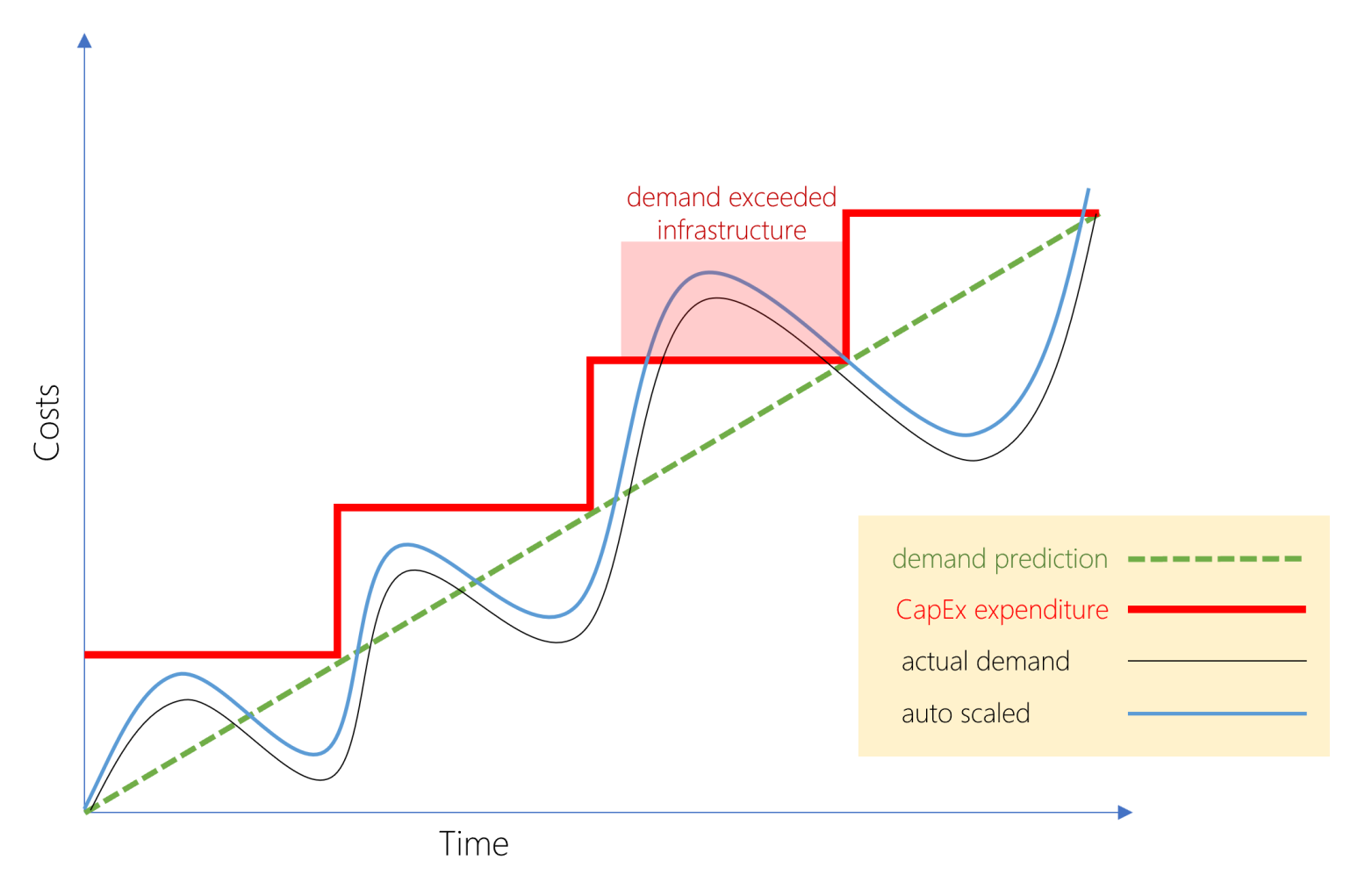
A media production house client faced this dilemma. Their video rendering workloads were massive and constant. Cloud rendering farms offered flexibility but came with eye-watering monthly bills during peak production cycles. After a detailed TCO analysis (factoring in hardware, power, cooling, and staffing), they invested in a dedicated on-prem rendering cluster. The upfront cost was steep, but their monthly operational expenses became highly predictable, and the 3-year TCO was projected to be 40% lower than the pure cloud alternative. This required careful capacity planning, something 1985 helped model based on their production pipeline data.
Actionable Takeaway: Model TCO rigorously for high-utilization, stable workloads. Don't just compare monthly cloud bills to hardware purchase prices. Factor in power, cooling, colocation/data center space, staffing, and the hardware refresh cycle (typically 3-5 years). Tool: Use a detailed TCO Calculator comparing On-Prem CapEx + OpEx vs. Cloud OpEx over a multi-year horizon.
Cloud-Native: The Double-Edged Sword of Agility
Moving to cloud-native architectures—microservices, containers, serverless—promises unparalleled development velocity and scalability. Done right, it’s transformative. Done wrong, it’s a labyrinth of dependencies, cascading failures, and operational nightmares. Agility has a price. Complexity.
The Microservices Tax: More Services, More Problems?
Breaking down a monolith into microservices sounds great on paper. Smaller, independent teams! Faster deployments! Technology diversity! But it introduces significant operational overhead: complex inter-service communication, distributed tracing challenges, sophisticated deployment strategies (Canary, Blue/Green), and the need for robust service discovery and configuration management. Research presented at IEEE conferences often highlights the challenges in testing and debugging distributed systems (Specific paper search needed for a direct link, e.g., searching "microservice testing challenges IEEE"). The cognitive load on developers increases.
One of our "rescue" projects involved a FinTech startup that adopted microservices aggressively... too aggressively. They had hundreds of tiny services, built by fragmented teams with inconsistent standards. Debugging a single user transaction required tracing calls across dozens of services, often involving multiple programming languages and databases. Their mean time to resolution (MTTR) for incidents was abysmal. At 1985, our first step wasn't adding features; it was implementing observability tooling (like Jaeger for tracing, Prometheus/Grafana for metrics) and enforcing stricter API contracts and documentation standards – what we call "taming the microservices zoo." We even recommended merging some overly granular services back together. Sometimes, fewer, well-defined services are better than a multitude of tiny, chaotic ones.
Actionable Takeaway: Don't adopt microservices just because it's trendy. Ensure you have the tooling, processes, and team maturity to manage the inherent complexity. Start with coarser-grained services and decompose further only when necessary.

Vendor Lock-In: The Comfortable Prison
Cloud providers make it incredibly easy to adopt their proprietary managed services—databases (DynamoDB, Firestore), messaging queues (SQS, Pub/Sub), AI/ML platforms (SageMaker, Vertex AI). These services offer convenience and reduce operational burden. Fantastic. Until you want to migrate. Or negotiate pricing. Relying heavily on proprietary services creates deep vendor lock-in, making future migrations expensive, complex, or practically impossible.
We saw this with an IoT company heavily invested in a specific cloud provider's IoT Core and time-series database offering. When a competitor offered significantly better pricing for similar capabilities, the switching cost was prohibitive. Rewriting their data ingestion pipeline and migrating years of historical data would have taken months and cost millions. They were stuck. As a VC focusing on enterprise tech commented privately: "We look closely at how much a startup relies on proprietary cloud services. Too much lock-in is a red flag for future M&A or strategic pivots."
Actionable Takeaway: Use managed services strategically, but always understand the exit path. Favor open-source alternatives (e.g., running PostgreSQL/MySQL on VMs or K8s instead of proprietary databases) where feasible. Abstract provider-specific logic behind interfaces in your code. Plan for multi-cloud or hybrid scenarios even if you're single-cloud today. Tool: Maintain an "Exit Strategy Document" for each critical managed service you adopt, outlining migration steps and estimated costs.
The Hybrid Path: Pragmatism or Purgatory?
For many established businesses, the answer isn't purely on-prem or purely cloud-native. It's hybrid—a mix of both, attempting to leverage the best of each world. Run stable, sensitive workloads on-prem; use the cloud for elastic, customer-facing, or experimental applications. Simple in concept. Devilishly complex in execution.

Stitching Worlds: The Integration Challenge
Making on-prem systems talk seamlessly and securely with cloud services is non-trivial. It requires careful network architecture (VPNs, Direct Connect/Interconnect), consistent identity and access management (IAM), and potentially complex data synchronization strategies. IDC data consistently shows strong growth in hybrid cloud adoption, but surveys also highlight integration complexity as a major hurdle. Where does data live? How is it secured in transit and at rest across environments? How do you ensure consistent performance?
1985 architected a hybrid solution for a large retailer. Their legacy inventory system (on-prem mainframe) needed to feed real-time stock levels to their new cloud-native e-commerce platform. Building a secure, reliable, and low-latency data bridge required significant effort involving message queues, API gateways, and careful network configuration. It wasn't a quick "plug-and-play" exercise; it was a dedicated engineering project requiring expertise in both legacy systems and modern cloud patterns.
Actionable Takeaway: Treat the hybrid integration layer as a first-class product, not an afterthought. Invest in robust networking, unified IAM, and potentially an Enterprise Service Bus (ESB) or API management platform to manage the seams. Tool: Use a Workload Placement Decision Matrix considering factors like data sensitivity, performance needs, elasticity requirements, and existing infrastructure.
One Pane of Glass? The Myth of Unified Hybrid Operations
Managing a hybrid environment doubles the operational complexity. You need tooling and expertise for both on-prem infrastructure (virtualization, storage, networking) and cloud services. Achieving true "single pane of glass" observability and management across both domains is challenging. Different monitoring tools, different deployment processes, different security paradigms. As one CTO of a financial services firm told us: "Hybrid isn't 'set it and forget it.' It requires a highly skilled Ops team comfortable navigating two distinct technological universes simultaneously."
At 1985, our SRE teams managing hybrid client environments emphasize standardized logging formats, federated metrics (pulling data from both on-prem and cloud monitoring into a central platform like Grafana or Datadog), and infrastructure-as-code (IaC) principles applied consistently across both sides where possible (e.g., using Terraform for both vSphere and AWS resources). It requires discipline and the right tooling stack.
Actionable Takeaway: Invest heavily in unified monitoring, logging, and automation tools that can span hybrid environments. Ensure your operations team has cross-domain expertise or structured collaboration processes. Don't underestimate the operational lift required. Tool: Implement a unified alerting strategy that correlates events from both on-prem and cloud systems.
Visual Break: Decision Matrix Snapshot
| Factor | On-Premises | Cloud-Native (Public Cloud) | Hybrid Cloud |
| Cost Model | High CapEx, Predictable OpEx | Low/No CapEx, Variable OpEx | Mix of CapEx/OpEx, Integration Costs |
| Scalability | Manual, Planned Capacity | Elastic, On-Demand | Elastic (Cloud part), Fixed (On-Prem) |
| Control | Full Control (Hardware, Network) | Shared Responsibility Model | High (On-Prem), Shared (Cloud) |
| Talent Needs | Traditional SysAdmin, Network Eng. | Cloud Architects, DevOps, SREs | Broad Skillset Across Both Domains |
| Compliance | Easier for Data Residency Control | Provider Certs, Audit Complexity | Complex Audit Trail |
| Agility/Speed | Slower Deployment Cycles | Faster Iteration, CI/CD Native | Variable, Depends on Integration |
| Vendor Lock-In | Low (Hardware/OS choices) | High Risk (Proprietary Services) | Moderate Risk (Integration Tools) |
| Complexity | Infrastructure Management | Distributed Systems, Cloud Services | Integration, Unified Operations |
The Bottom Line: Context is King
There is no single "better" answer in the on-prem vs. cloud-native debate. Anyone selling you one is selling snake oil. The optimal choice hinges entirely on your specific business context, risk appetite, regulatory constraints, workload characteristics, and team capabilities.
- Need absolute control over sensitive data and predictable costs for stable workloads? On-prem (or private cloud) might be your best bet.
- Need rapid scalability, global reach, and access to cutting-edge managed services for variable workloads? Cloud-native is likely the path.
- Have significant legacy investments but need cloud agility for new initiatives? Hybrid is probably your reality, but tread carefully.
The real challenge isn't picking a platform; it's architecting a solution that aligns with your strategy and executing it flawlessly. It’s about understanding the trade-offs, mitigating the risks, and building operational excellence, regardless of where your infrastructure lives.
If your current dev partner can't articulate the TCO pitfalls of cloud egress, the operational cost of microservice complexity, or the specific compliance nuances driving hybrid decisions, you might have the wrong partner.
At 1985, we live in these trenches daily. We help leaders like you navigate these complex decisions, architect resilient systems, and build high-performing engineering teams—whether on-prem, in the cloud, or straddling both.
Ready for a partner who understands the nuances beyond the buzzwords? Let's talk strategy. Ping 1985.


