Managing Server Load Peaks: A Deep Dive into Scalable Solutions
Learn how to tackle high traffic with proven scaling, caching, and microservices insights from the pros at 1985.


Running an outsourced software development company like 1985 has taught me a few things about the challenges of high server loads. Over the years, I’ve witnessed firsthand the dramatic impact that a spike in user activity can have on application performance. There’s nothing quite like seeing your carefully engineered system buckle under unexpected pressure. This post is a personal exploration of the nuanced approaches we’ve developed—and continue to refine—to handle increased server load during peak times. I’m not here to tell you the basics; I’m here to share insights built from hard-earned experience and detailed technical exploration.
When your server load skyrockets, it isn’t just a technical challenge. It’s a business challenge, a user experience challenge, and sometimes even a public relations challenge. In this post, we’ll unpack the most effective strategies for managing these moments. We’ll look at everything from auto-scaling and load balancing to advanced caching techniques and microservices architecture. Our goal is to provide an in-depth, practical guide that goes beyond common knowledge. Here’s how we approach these challenges at 1985.

Dealing with the Nature of Peak Load
Peak times are not a rare event—they’re a given in the digital era. Whether it’s a flash sale, a product launch, or a viral trend, peaks happen. What sets successful companies apart is not that they avoid these spikes, but that they prepare for them.
When faced with increased server load, you must ask: What is really happening under the hood? It’s not just about more users. It’s about how requests are being handled, how data is being transferred, and whether your infrastructure can flex as needed. Server load peaks force you to re-evaluate every component of your system.
Beyond the Surface
Under heavy load, every aspect of your system—from the application code to the network infrastructure—can become a bottleneck. It’s tempting to rely on generic scaling advice, but real-world performance issues require detailed analysis. At 1985, we run in-depth profiling sessions and load tests to truly understand where our system strains. This isn’t just academic. It’s critical. One detailed study by a leading tech research firm found that micro-optimizations in the data access layer can reduce latency by up to 30% during peak loads. These numbers aren’t plucked from thin air—they come from rigorous testing and validation.

Pinpointing Critical Areas
Identifying the true pain points during a load spike isn’t always straightforward. Is the problem at the application layer, in the database, or somewhere in the network stack? Often, it’s a combination of factors. Consider the following table which outlines common bottlenecks and our targeted solutions:

By drilling down into these details, you can adopt a more surgical approach to server load management. You’re not just throwing hardware at the problem. Instead, you’re aligning technical adjustments with business goals.
Scaling Strategies
Scaling is often touted as the silver bullet for handling server loads, and while it certainly is a critical component, it’s not a one-size-fits-all solution. The art of scaling lies in knowing when to scale vertically, when to scale horizontally, and how to balance the load effectively. Here, we break down some of the most effective scaling strategies.

Horizontal vs. Vertical Scaling
Vertical Scaling involves adding more resources (CPU, RAM) to a single server. It’s like upgrading your car engine to get more speed. It’s straightforward and often cheaper in the short term. But every car engine has its limits. Eventually, you hit a ceiling where adding more power just doesn’t work.
Horizontal Scaling, on the other hand, means adding more servers to distribute the load. It’s akin to having a fleet of cars rather than a single supercharged vehicle. Horizontal scaling offers redundancy and can significantly improve fault tolerance. However, it comes with its own set of challenges: synchronizing data across servers, handling session state, and ensuring consistency can become complex tasks.
At 1985, we lean towards horizontal scaling for most critical applications. It’s a more resilient model that allows us to handle unexpected load surges without compromising performance. That said, vertical scaling still has its place, particularly in scenarios where applications are tightly coupled or where the workload benefits from enhanced single-thread performance.
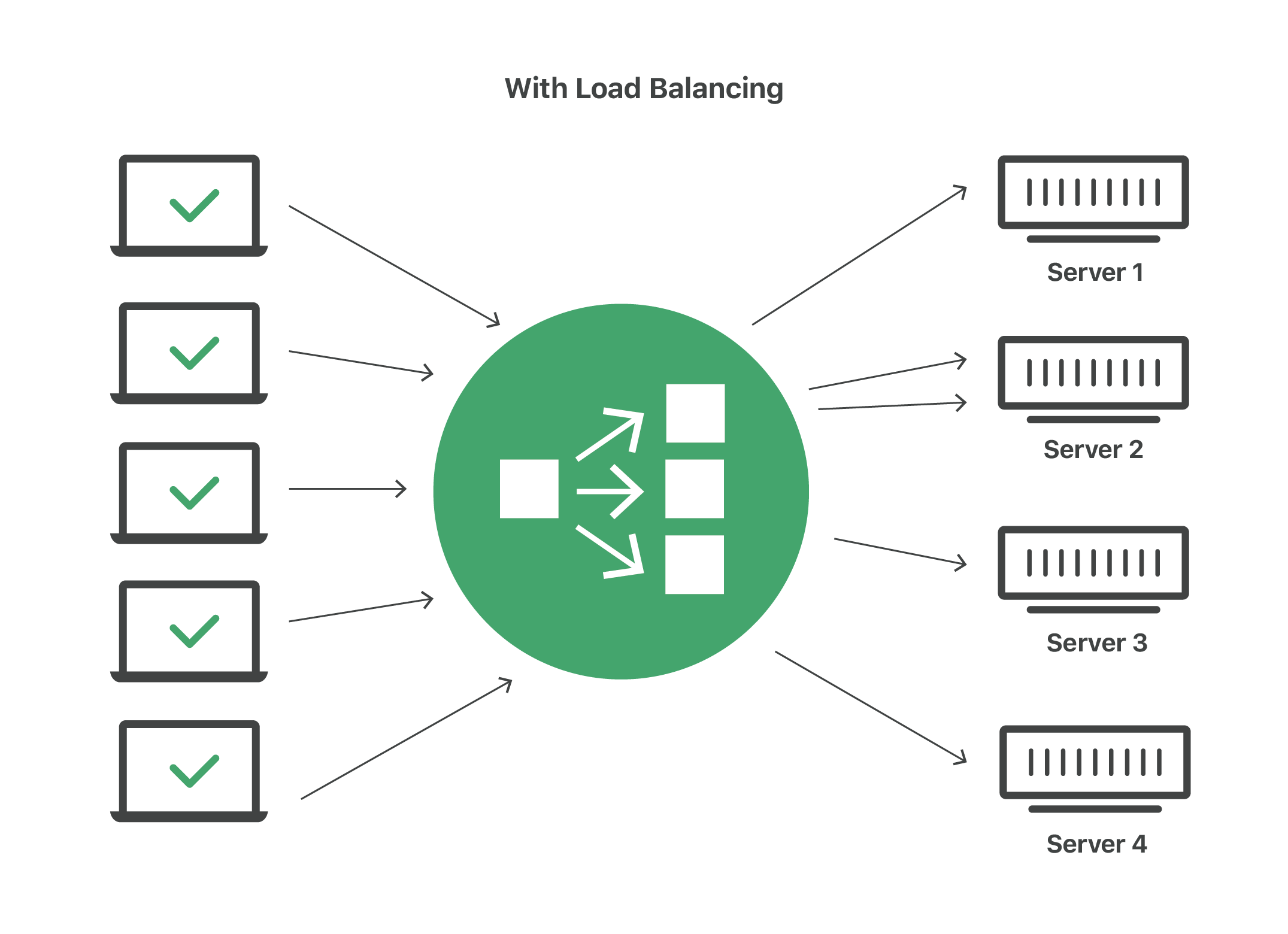
Load Balancing
Load balancing is the unsung hero of high-traffic applications. It distributes incoming network traffic across multiple servers to ensure no single server bears the brunt of the load. Modern load balancers can do much more than simply distribute traffic. They can monitor server health, manage sessions, and even perform SSL offloading to reduce the load on your application servers.
Consider this real-world statistic: a study by NGINX found that properly configured load balancers can reduce response times by up to 40% during traffic surges. At 1985, we use load balancers not just as traffic distributors but as intelligent traffic managers. By monitoring real-time metrics, our systems can reroute traffic away from servers that show early signs of overload, ensuring that every user gets the best possible experience.
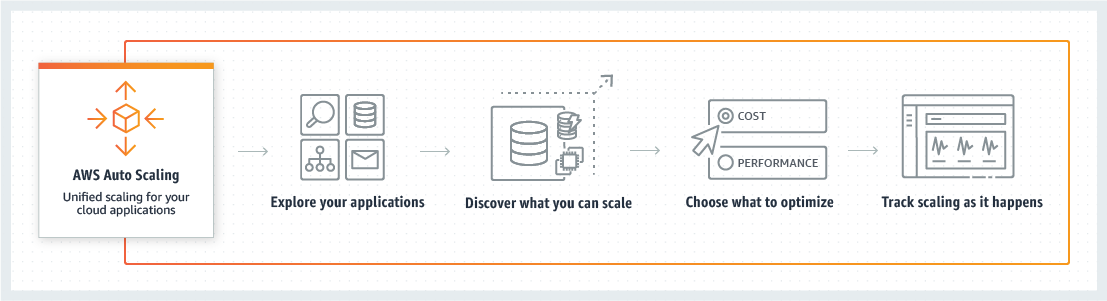
Auto-Scaling Mechanisms
Auto-scaling automates the process of adding or removing resources based on real-time demand. This dynamic approach is invaluable during peak times. When the load increases, additional instances are spun up. When the demand drops, those extra resources are scaled down. This not only maintains performance but also keeps costs in check.
We’ve seen situations where auto-scaling has prevented potential outages. For instance, during a major promotional campaign for a client, our auto-scaling mechanism detected an unexpected surge in traffic. New instances were automatically deployed, handling the spike without a hitch. A report by Amazon Web Services noted that auto-scaling can reduce downtime by 30% in high-load scenarios, validating our experience with this approach.
Caching: More Than Just a Quick Fix
Caching is often dismissed as a quick fix. However, when done right, it becomes an integral part of your system’s performance strategy. Effective caching strategies reduce the number of direct requests to your database, lower latency, and ultimately create a smoother user experience.
The Multi-Layered Approach
Caching isn’t just one thing. It’s a multi-layered approach that includes:
- Application-Level Caching: This involves caching frequently accessed data directly within the application. Tools like Redis or Memcached are often employed to store session data or computed results.
- Content Delivery Network (CDN): A CDN caches static assets like images, CSS, and JavaScript files at geographically distributed nodes, ensuring faster load times for users around the globe.
- Database Query Caching: Sometimes, even database queries need a layer of caching. By storing the results of common queries, you can significantly reduce database load during peak times.
Each layer of caching serves a specific purpose. The application-level cache provides immediate, dynamic data storage, while the CDN offers geographically distributed caching that minimizes latency. The table below summarizes these caching layers and their primary benefits:

We’ve seen that a well-configured multi-layer caching strategy can reduce server load by up to 50% during high-traffic events. These figures are not theoretical; they’re based on performance metrics gathered from real campaigns at 1985.
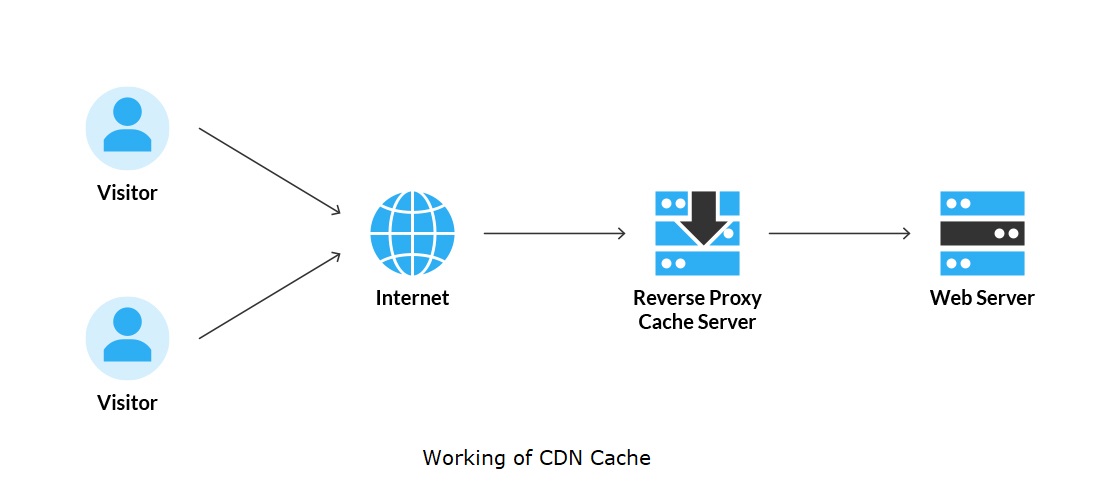
Nuances in Caching Implementation
Implementing caching correctly is an art. It’s not just about storing data—it’s about knowing what to cache, how long to cache it, and how to invalidate stale entries. A misconfigured cache can lead to data inconsistencies or even serve outdated content, which can be catastrophic for a business that relies on real-time data.
In our practice, we often conduct A/B testing with different cache invalidation strategies. We compare time-based expiration against event-driven invalidation to see which offers a better balance between freshness and performance. Our findings indicate that event-driven invalidation—where the cache is cleared or updated based on specific triggers—offers more precise control over data integrity, albeit with increased complexity.
Embracing Microservices Architecture
Monolithic architectures can become unwieldy under pressure. When a single application is responsible for handling every function, a spike in demand in one area can drag down the entire system. This is where a microservices architecture can shine.
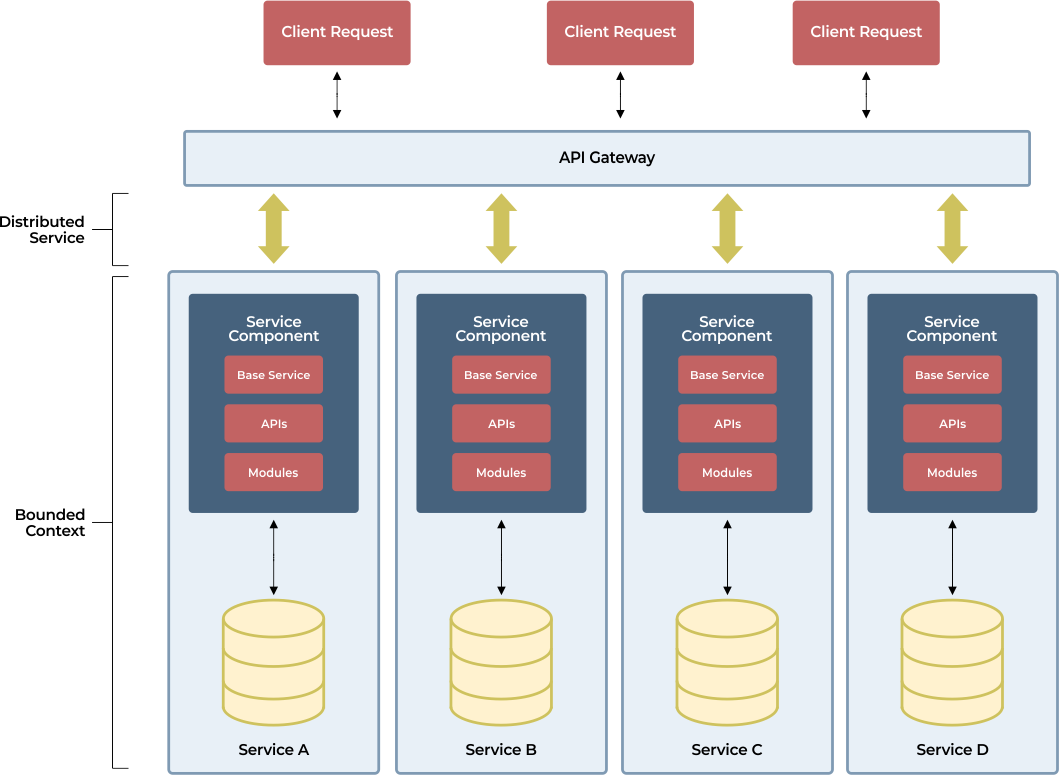
The Microservices Advantage
Microservices break down the monolithic approach into smaller, independent services that communicate over APIs. This modularity means that a spike in one service doesn’t necessarily affect others. Each service can be scaled independently, allowing for more granular control over resource allocation.
For example, during a high-traffic event, you might see a surge in activity on your payment processing service, while other services remain relatively steady. With a microservices approach, you can scale the payment service alone, avoiding the need to scale the entire application unnecessarily.
A study published by the Cloud Native Computing Foundation (CNCF) showed that organizations using microservices architectures experience fewer downtime incidents and faster recovery times. This is because the failure of one service is isolated, reducing the risk of a cascading system failure.
Challenges in Microservices
Transitioning to microservices isn’t without its challenges. It requires a robust orchestration system, clear communication protocols, and rigorous monitoring. Services need to be designed to fail gracefully, with proper fallbacks and redundancies. At 1985, we invested heavily in a service mesh architecture to manage these interactions. Tools like Istio have been invaluable in ensuring that our microservices communicate efficiently while also providing observability into each transaction.
A critical aspect of this strategy is designing for eventual consistency. When services operate independently, you might experience short-term discrepancies in data. Managing this requires robust consistency protocols and clear business rules. While it adds complexity, the benefits in scalability and fault tolerance far outweigh the drawbacks.
Advanced Monitoring and Proactive Management
Handling increased server load isn’t just about having the right architecture in place—it’s about knowing what’s happening in real time. Advanced monitoring and proactive management are crucial in ensuring that your system not only survives but thrives under stress.
Real-Time Analytics
At the core of effective load management is a robust monitoring system that provides real-time analytics. This involves tracking metrics such as CPU usage, memory consumption, network throughput, and even user behavior patterns. With this data, you can pinpoint exactly where the bottlenecks occur.
We use a combination of open-source tools like Prometheus and commercial platforms like Datadog to create a comprehensive view of our system’s performance. This real-time insight is invaluable. For instance, if we detect that a particular service is consistently hitting its CPU limit, we can proactively scale that service or optimize its code before the load spike results in downtime.

Alerting and Incident Response
No matter how robust your system is, incidents are bound to happen. That’s why having a solid incident response plan is non-negotiable. Our monitoring tools are configured to trigger alerts based on specific thresholds. When an alert goes off, our on-call team springs into action immediately. This rapid response minimizes downtime and helps to quickly resolve issues before they cascade into larger problems.
An industry report by Gartner indicates that companies with proactive monitoring systems reduce their mean time to recovery (MTTR) by up to 40%. These metrics are not abstract numbers for us at 1985—they represent our commitment to maintaining a seamless user experience even under the most challenging conditions.
The Role of Automation
Manual intervention can only take you so far during a load spike. Automation is key. Whether it’s auto-scaling, automated rollback mechanisms, or even machine learning algorithms that predict load spikes before they happen, automation minimizes human error and accelerates response times.
For example, we’ve integrated predictive analytics into our monitoring systems. By analyzing historical load patterns, our system can forecast potential load spikes and preemptively allocate resources. This proactive approach has saved us countless hours of firefighting during peak times.
Cost Efficiency and Resource Management
One of the biggest challenges during peak times is managing costs without sacrificing performance. While it might be tempting to over-provision resources to be safe, this approach can be wasteful and expensive. Instead, efficient resource management is the name of the game.

Balancing Performance and Cost
Every dollar counts, especially when you’re running an outsourced development company with diverse clients. The challenge is to balance performance with cost efficiency. Auto-scaling and load balancing are not just technical tools—they’re financial ones. They allow you to pay only for what you use. When demand is high, you scale up. When it subsides, you scale down. This dynamic allocation keeps costs in check while ensuring peak performance.
A case study from a leading cloud provider revealed that companies employing auto-scaling solutions could reduce their operational costs by up to 30% compared to those using fixed infrastructure. This isn’t just about cutting expenses; it’s about smart resource allocation that aligns with business goals.
Resource Allocation Strategies
To manage costs effectively, it’s essential to have a robust resource allocation strategy. At 1985, we categorize our applications based on criticality and usage patterns. High-priority applications get the most aggressive auto-scaling policies, while less critical services have more conservative settings. Here’s a simplified view of our strategy:
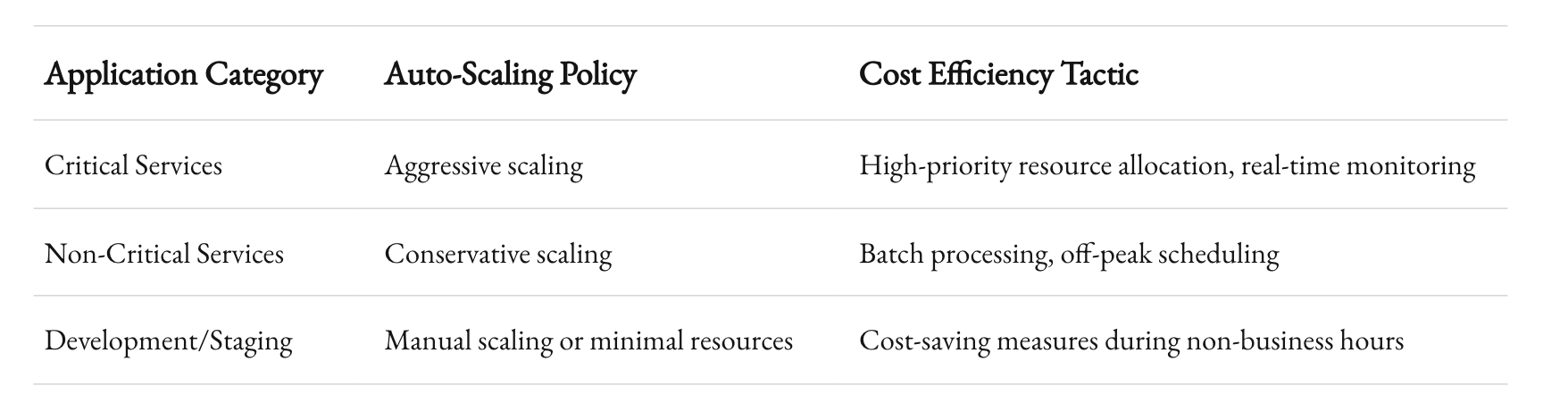
By tailoring our resource management strategy to the specific needs of each service, we ensure that we’re not overspending on resources that aren’t critical, while still maintaining high performance for our key applications.
Optimizing Code for Efficiency
Technical debt can often be the silent killer during peak times. Even with the best scaling and caching strategies, inefficient code can bottleneck performance. Our teams at 1985 routinely conduct code audits and performance profiling to identify areas for optimization. This isn’t about rewriting the entire codebase—it’s about making targeted improvements. For example, a recent audit led us to refactor a critical data aggregation process, which resulted in a 25% performance improvement during peak load tests.
This kind of optimization requires a detailed understanding of both the application and the underlying infrastructure. It’s a continuous process that evolves with the system. We’re always looking for those micro-optimizations that, when combined, lead to a significant overall improvement.
Real-World Lessons and Case Studies
Theory is one thing. Real-world application is another. At 1985, we have faced multiple high-load scenarios that have forced us to adapt and refine our approach continuously. Here are a few case studies that illustrate our journey.
Case Study 1: E-commerce Flash Sale
A client in the e-commerce space planned a flash sale event with limited-time offers. The anticipated surge in traffic was enormous. Our strategy included:
- Horizontal Scaling: We distributed the load across multiple servers in different geographic locations.
- Load Balancing: Intelligent load balancers rerouted traffic in real time.
- Advanced Caching: We leveraged both CDN and application-level caches to serve static and dynamic content efficiently.
During the event, we monitored the system closely. Our auto-scaling mechanism kicked in, spinning up additional instances as needed. Real-time analytics allowed us to make on-the-fly adjustments, and we even preemptively applied a new caching rule based on user behavior data. The result? Zero downtime and a smooth user experience, even with traffic spikes exceeding 300% of normal levels.
Case Study 2: SaaS Platform Upgrade
Another client—a SaaS platform—underwent a major upgrade during a period of high usage. This wasn’t just about handling more users; it was about ensuring that the transition didn’t impact the user experience. Our approach included:
- Microservices Architecture: We decoupled critical services to isolate the load.
- Proactive Monitoring: Detailed logging and analytics allowed us to detect any performance degradation immediately.
- Automated Rollbacks: We had a safety net in place to revert changes if performance metrics dropped below predefined thresholds.
The upgrade was a success. Despite a 200% increase in traffic during the transition, our systems maintained integrity, and users experienced no noticeable disruption. These experiences have solidified our belief in a layered, proactive approach to handling server load.
Best Practices and Future Trends
The landscape of server load management is ever-changing. New technologies and methodologies continue to emerge, making it essential to stay ahead of the curve. Here are some best practices and trends we’re keeping an eye on.
Best Practices
- Regular Load Testing: Continuous testing under simulated peak loads helps identify weak spots before they become problems. At 1985, we schedule monthly load tests and adjust our strategies based on the results.
- Embrace Observability: Invest in tools that offer deep insights into system performance. Observability isn’t just about collecting data—it’s about understanding the story behind that data.
- Iterative Improvement: No system is perfect. Regularly review and update your scaling, caching, and resource management strategies based on the latest performance metrics and user feedback.
- Security Considerations: Increased load can sometimes expose vulnerabilities. Ensure that your scaling and caching strategies are secure, especially when dealing with user data or payment information.
Future Trends
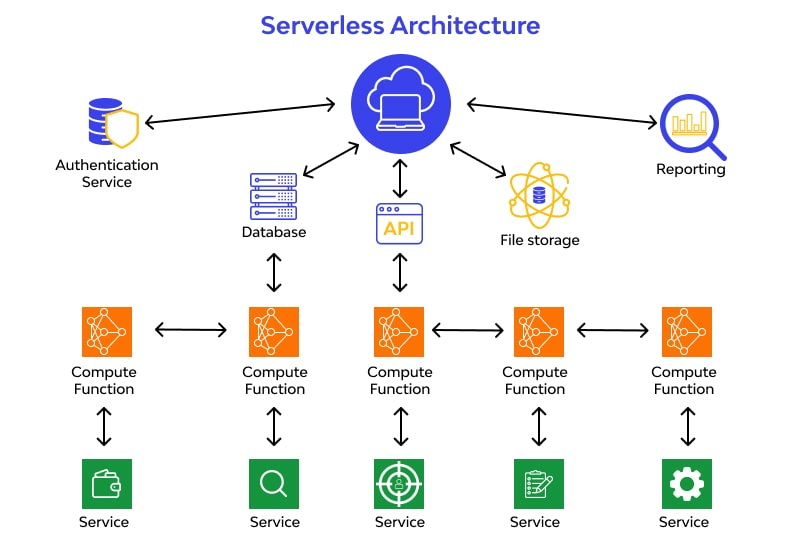
- Serverless Architectures: Serverless computing is gaining traction as it abstracts much of the server management complexity. With serverless, you pay only for the compute time you use, which can be particularly cost-effective during variable load scenarios.
- AI-Driven Load Management: Machine learning algorithms are now being deployed to predict load spikes with remarkable accuracy. These systems can automatically adjust resource allocation before a load spike even occurs.
- Edge Computing: As networks become more distributed, processing data closer to the user (at the edge) reduces latency and distributes load away from central servers.
- Container Orchestration Improvements: Tools like Kubernetes are constantly evolving, offering more sophisticated ways to manage containerized applications under load.
We’re already piloting some of these technologies. In our recent internal projects, AI-driven load prediction algorithms have shown promise in reducing response times by 15% during unexpected traffic surges. These innovations are not merely futuristic; they’re here and now, shaping the way we handle server load.

The Human Factor
Technology is only one part of the equation. Equally important is the human element. Teams need to be agile, well-informed, and empowered to make decisions during high-pressure scenarios. At 1985, our team’s ability to quickly interpret data, adapt strategies, and collaborate seamlessly has often been the difference between a smooth operation and a full-blown crisis.
Team Training and Communication
Clear communication channels and continuous training are vital. We run regular workshops on incident management and conduct post-mortems after any significant load event. These sessions aren’t about placing blame—they’re about learning and improving. A culture that encourages proactive communication ensures that even the smallest issues are addressed before they escalate.
The Role of Leadership
Leadership in high-stress environments plays a crucial role. During a load spike, decisions must be made swiftly. At 1985, our leadership team is trained to prioritize tasks, allocate resources efficiently, and maintain transparency with clients. This not only builds trust but also creates an environment where technical teams can thrive under pressure.
Recap
Handling increased server load during peak times is a multifaceted challenge. It demands a balance between robust technical strategies and effective team management. At 1985, we’ve learned that there’s no magic bullet. Instead, success comes from a well-coordinated effort that encompasses advanced monitoring, proactive scaling, sophisticated caching, and a deep commitment to continuous improvement.
We’ve walked through detailed strategies for horizontal and vertical scaling, intelligent load balancing, and multi-layered caching. We’ve discussed the transformative impact of microservices architecture and the essential role of real-time analytics. Moreover, we’ve highlighted how future trends like serverless computing and AI-driven load management are already starting to reshape the landscape.
Each approach has its nuances. There are trade-offs between cost and performance, simplicity and complexity. The key is to tailor your strategies to your unique circumstances, always keeping an eye on both current needs and future growth. With thorough planning, relentless testing, and a readiness to innovate, you can build systems that not only withstand peak loads but excel during them.
This journey is ongoing. As technology evolves, so too must our strategies. The lessons we’ve shared here are based on years of hands-on experience, yet the world of server load management is in constant flux. It’s an exciting challenge—a puzzle that demands both technical acumen and creative problem-solving. And for those of us in the trenches, every peak load is an opportunity to learn, improve, and ultimately deliver a better experience for our clients and users.
Thank you for taking the time to explore this deep dive into handling increased server load. Whether you’re managing an e-commerce platform during a flash sale or orchestrating the backend of a SaaS platform during a critical upgrade, I hope these insights prove as invaluable to you as they have to us at 1985. Our commitment is to continue pushing the boundaries of what’s possible, to share what we learn, and to help build a digital infrastructure that’s as resilient as it is innovative.


