How to Future-Proof Your AI Stack
Stay ahead of the curve with friendly, real-world advice on future-proofing your AI infrastructure.


Over the last few years, we’ve seen our clients wrestle with a big question: How do we build AI solutions that survive the rapid pace of technological change? This isn’t a trivial dilemma. AI has matured faster than many of us predicted, and the infrastructure behind it faces constant disruption. One day your existing setup feels rock-solid. The next, you’re elbow-deep in a new wave of computing hardware, data orchestration challenges, and advanced machine learning frameworks that make your “cutting-edge” pipeline look outdated.
We’ve been lucky to be on the ground floor of many AI projects. We’ve seen success stories where nimble teams pivot quickly and embrace new architectures. We’ve also seen cautionary tales. Some companies double down on a single vendor or a single machine learning framework. They soon realize that vendor’s ecosystem no longer meets their needs, or that the framework can’t handle next-generation workloads. It’s painful to watch. It’s even more painful to experience first-hand.
I believe in taking a forward-looking approach to AI infrastructure. This isn’t about blindly chasing the latest fad. It’s about building systems that can integrate emerging technologies with minimal friction. It’s about anticipating shifts in hardware, compute strategies, data governance, and even the regulatory environment. And it’s about scaling gracefully—both up and down—without tearing everything apart every time you need to adapt.

That’s the focus of this post. In the paragraphs that follow, we’ll cut through some of the noise and talk about real-world strategies that keep your AI stack resilient. We’ll explore trends that matter, from specialized hardware to advanced DevOps pipelines. We’ll look at how some organizations are rolling out AI without painting themselves into a corner. And we’ll dig into how you can position your company to be ready for whatever’s next—be it quantum computing or the next wave of large-scale language models.

I’ll also bring in insights we’ve gathered at 1985. We’ve helped everyone from lean startups to Fortune 500s navigate these waters. There’s no one-size-fits-all approach, but there are patterns, pitfalls, and best practices worth sharing.
The Current Reality
AI is now table stakes for many industries, whether that’s healthcare leveraging deep learning for diagnostic imaging or finance using NLP to parse mountains of regulatory data. Companies are pouring resources into AI initiatives. According to Deloitte’s “State of AI in the Enterprise” report, 74% of businesses consider AI “critical” to their success in the next five years. That’s a big number. It underscores how deeply AI is becoming woven into corporate strategies.

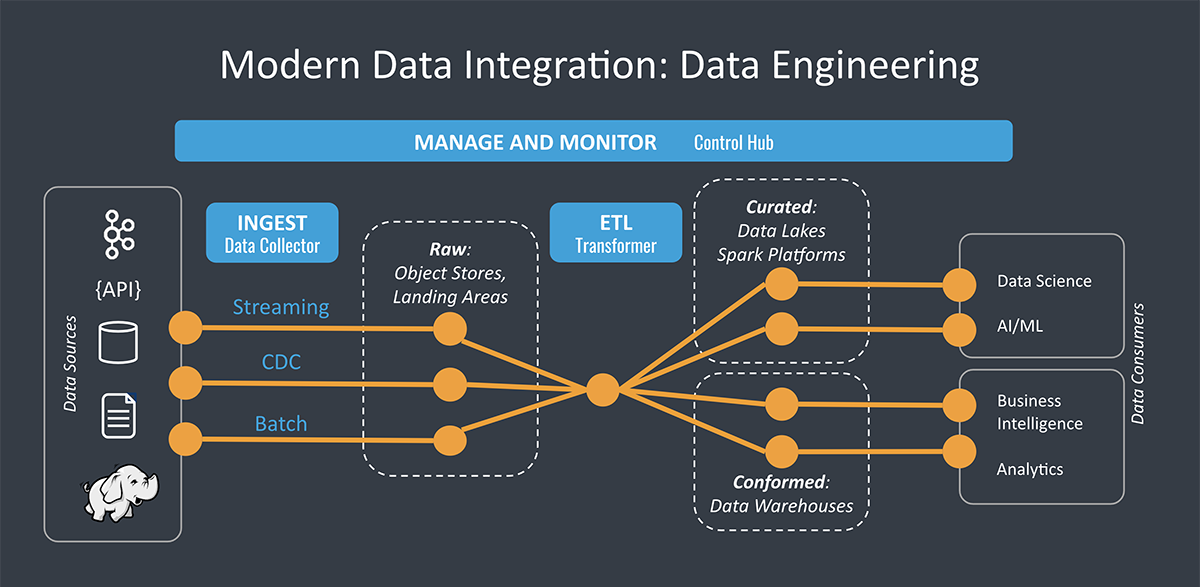
Yet, the infrastructure supporting these AI initiatives doesn’t always get the attention it deserves. Leaders often focus on the final model, the shiny app, or the story they can tell stakeholders. They forget the messy details that power everything. Data pipelines, container orchestration, GPU clusters, and advanced MLOps frameworks might not be as glamorous as a cutting-edge chatbot. But skip them, and your progress stalls.
There’s another reality: AI isn’t just about big data anymore. Today’s AI involves structured, semi-structured, and unstructured data flowing in from multiple channels. It can involve real-time edge computing or pre-processed data from multiple vendor APIs. That data, in turn, powers advanced models that can train on text, images, audio, and tabular data in the same breath. This complexity strains legacy infrastructure designed for narrower tasks.
At the same time, we’re seeing a shift toward specialized hardware. CPUs aren’t always enough. GPUs, TPUs, NPUs, and even FPGAs are increasingly on the table. If your stack was built around CPU-based clusters and you haven’t engineered a path to hardware acceleration, you risk falling behind. This trend isn’t going away. In fact, NVIDIA recently released the H100 GPU, which can handle massive models faster than ever before. Other hardware manufacturers are closing in. This competition will spark new waves of computing architecture changes over the next few years.
For companies that want to stay ahead, the message is clear: don’t lock yourself into a rigid ecosystem. Your data ingestion layer, pipeline orchestration, model training environment, and deployment tools need to talk to each other seamlessly. But they also need to be open to change. Think of your AI infrastructure like a living organism. If it stops evolving, it dies.
Emerging Challenges
The Hardware Shuffle
It used to be that you just spun up a cluster of CPUs and maybe a few GPUs for training. That’s no longer enough. Hybrid GPU/CPU setups are common, but advanced AI workloads might demand more. If you’re venturing into speech recognition at scale or training large language models, specialized chips like TPUs (Tensor Processing Units) can accelerate computations. Some projects may benefit from smaller, low-power edge AI hardware, especially in IoT scenarios.
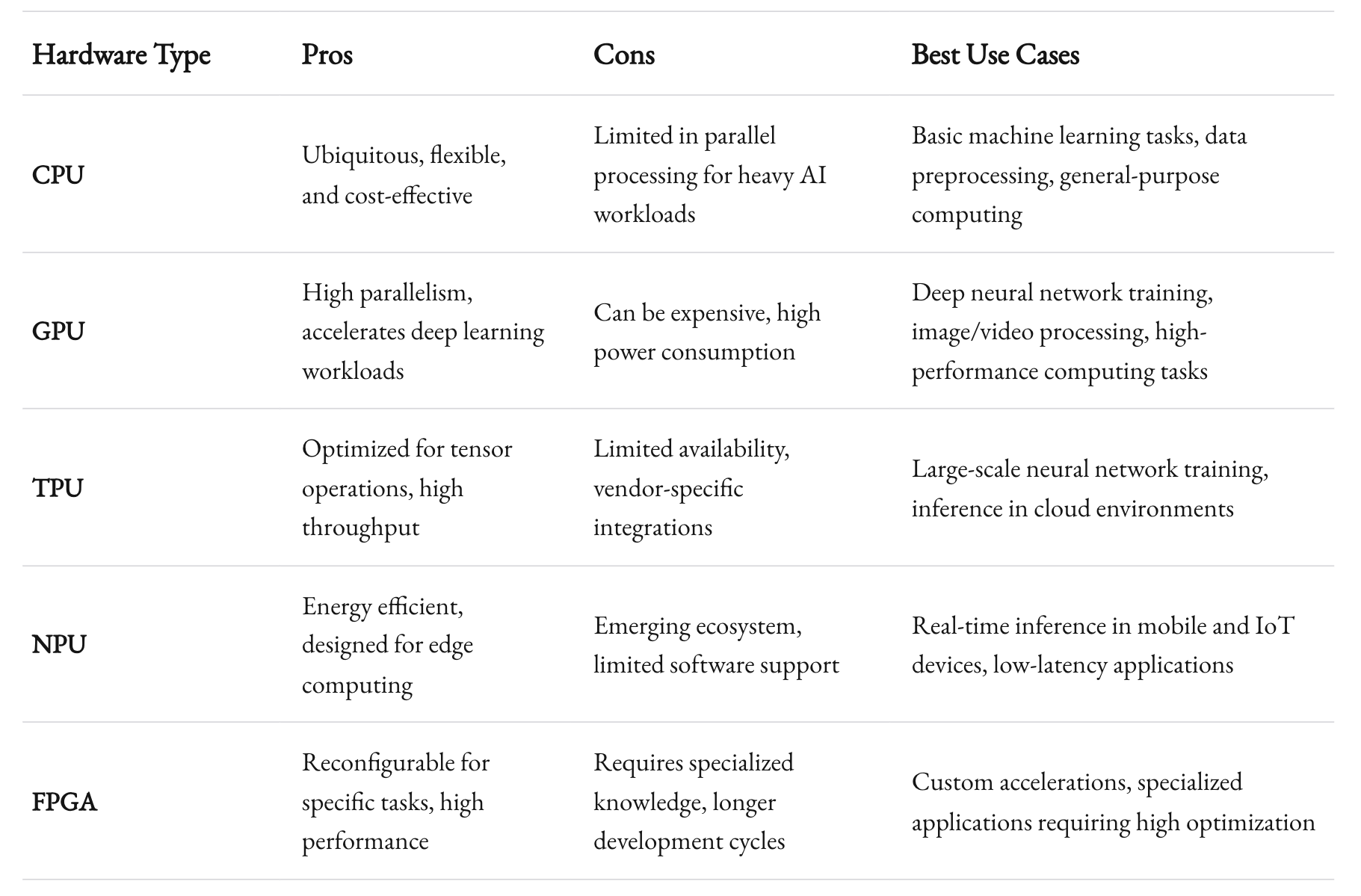
What does this mean for you? It means the hardware environment is fluid. Gone are the days when you chose a single vendor and stuck with it for a decade. If you’re building an AI stack that must last, ensure it can handle different types of hardware accelerators. Look at container orchestration platforms that support heterogeneous environments. Investigate how various clouds (AWS, Azure, GCP) handle GPU and TPU usage. And, if you’re hosting on-prem, verify that your data center can adapt to the power and cooling requirements of cutting-edge chips.
The Rise of MLOps Complexity
Machine learning operations (MLOps) used to be an afterthought. Data scientists churned out models, tossed them over the fence, and DevOps teams tried to shoehorn them into production. That might have worked when you had a handful of models. Today, enterprises can have hundreds or thousands of models in the wild. Some might be deep neural networks. Others might be simpler logistic regressions used for quick decision making.

Each model has its own data sources, training cycles, and update requirements. Failure to manage these systematically leads to chaos. The industry has responded by creating a wave of MLOps tools—like Kubeflow, MLflow, and Amazon SageMaker. But plugging these into a legacy CI/CD pipeline can be messy. The key question becomes: Do we have a well-thought-out plan to continuously integrate, deploy, monitor, and refine machine learning models across multiple environments?
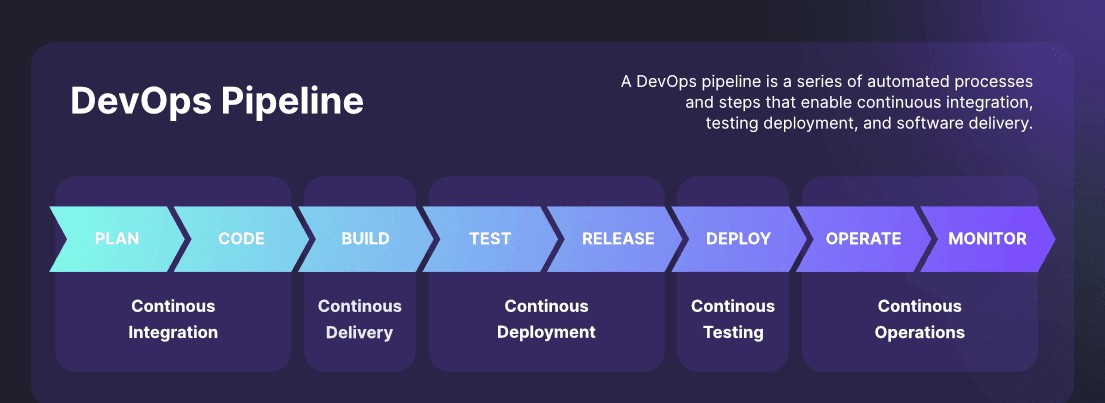
Data drifting away from your training distribution, untracked model updates, or poor governance can all lead to negative outcomes. Think about how high-frequency trading algorithms can go off the rails if the market regime changes. The cost of ignoring MLOps best practices is high. It’s not just about technical debt. It could be about regulatory compliance and reputational damage if a model’s predictions harm users or expose sensitive data.
Strategies for a Future-Proof AI Stack
Adopting a Layered Architecture
The best AI stacks I’ve seen treat infrastructure like layers. Data ingestion, data processing, model training, model deployment, and monitoring each occupy separate layers. Each layer relies on common interfaces to talk to the layers above and below. If you adopt this approach, you can swap out one layer without ripping out everything else. Suppose you decide to move from a CPU-based cluster to a specialized GPU cluster for training. A well-designed layer boundary means your pipelines for data ingestion and model deployment remain mostly unchanged.

This layered design also helps with vendor neutrality. Maybe you start with AWS for training your models. Later, you find Azure is better for your specific hardware acceleration needs. If your training layer is designed to be portable, you switch providers with fewer headaches. If your data ingestion pipeline is built on an open framework like Apache Kafka, you can point it to different training environments.
Focus on consistent APIs and containerized environments. Docker or Kubernetes-based deployments can ensure that your layers talk through container boundaries. This approach fosters modularity and reduces friction.
Embracing Open Standards and Interoperability
One of the biggest mistakes I see is locking into proprietary tools too early. Sure, a vendor might promise an all-in-one solution that handles data ingestion, feature engineering, training, and deployment. It sounds tempting, especially when you have a million other things to do. But you pay for it later. Maybe that vendor doesn’t keep pace with the newest hardware accelerators. Maybe they don’t support advanced frameworks like PyTorch for specialized tasks.
Look for open standards. Onnx (Open Neural Network Exchange), for instance, makes it easier to port models between frameworks. Tools like MLflow or Kubeflow are open source, offering flexibility and an active community. Kubernetes is a de facto standard for container orchestration, so it’s widely supported.

Interoperability matters beyond just software. If your design can’t switch from one hardware type to another, you risk painting yourself into a corner. Don’t pick a specialized chip that has zero support from mainstream frameworks unless you’re absolutely sure you can sustain it. Keep a fallback path.
Practical Implementation Tactics
Data-Centric Approach
I love to focus on data quality before model complexity. High-quality data often beats fancy algorithms trained on garbage. This principle becomes even more critical when future-proofing your stack. Models come and go. Data endures. Whether your next step is reinforcement learning or advanced generative modeling, well-managed data pipelines remain the backbone.
Implement a robust data versioning system. Tools like DVC (Data Version Control) or Delta Lake from Databricks can track changes in your datasets. This ensures your future models have a historical trail. It also means you can revert to a specific data snapshot if a newer dataset introduces unexpected quirks.
On top of this, take data governance seriously. According to a 2022 Gartner report, poor data quality costs organizations an average of $12.9 million annually. That’s a staggering figure. Ensuring compliance with privacy regulations (like GDPR and CCPA) is essential, especially if you plan to scale globally. A flexible data architecture that supports encryption, anonymization, and auditing is a must.
The MLOps Pipeline: More Than Just CI/CD
An MLOps pipeline isn’t just a rebranded DevOps pipeline. There are extra steps: data validation, feature store management, experiment tracking, model performance metrics, automated retraining, and drift detection. Each step requires a specialized approach. If you’re not tracking data drift, you can deploy a model that works well today but crumbles tomorrow when real-world data changes.
Experiment tracking is vital. Tools like MLflow let you log hyperparameters, evaluation metrics, and code commits. When your next wave of ML engineers arrives, they shouldn’t have to guess which hyperparameters you used a year ago. The more transparent your experimentation, the easier it is to maintain consistent performance across a shifting landscape of new frameworks and hardware.
Continuous training can be a double-edged sword. Automating the retraining of models can keep you up to date. But be sure you have guardrails. If your pipeline blindly retrains on new data without robust QA, you risk pushing flawed models into production. Put checks in place. For instance, use automated testing frameworks that compare new model performance against a baseline. If performance dips below a certain threshold, the pipeline halts. A human reviews the situation. This approach might seem cautious, but it can save you from big mistakes later.
Choosing Your Infrastructure Wisely
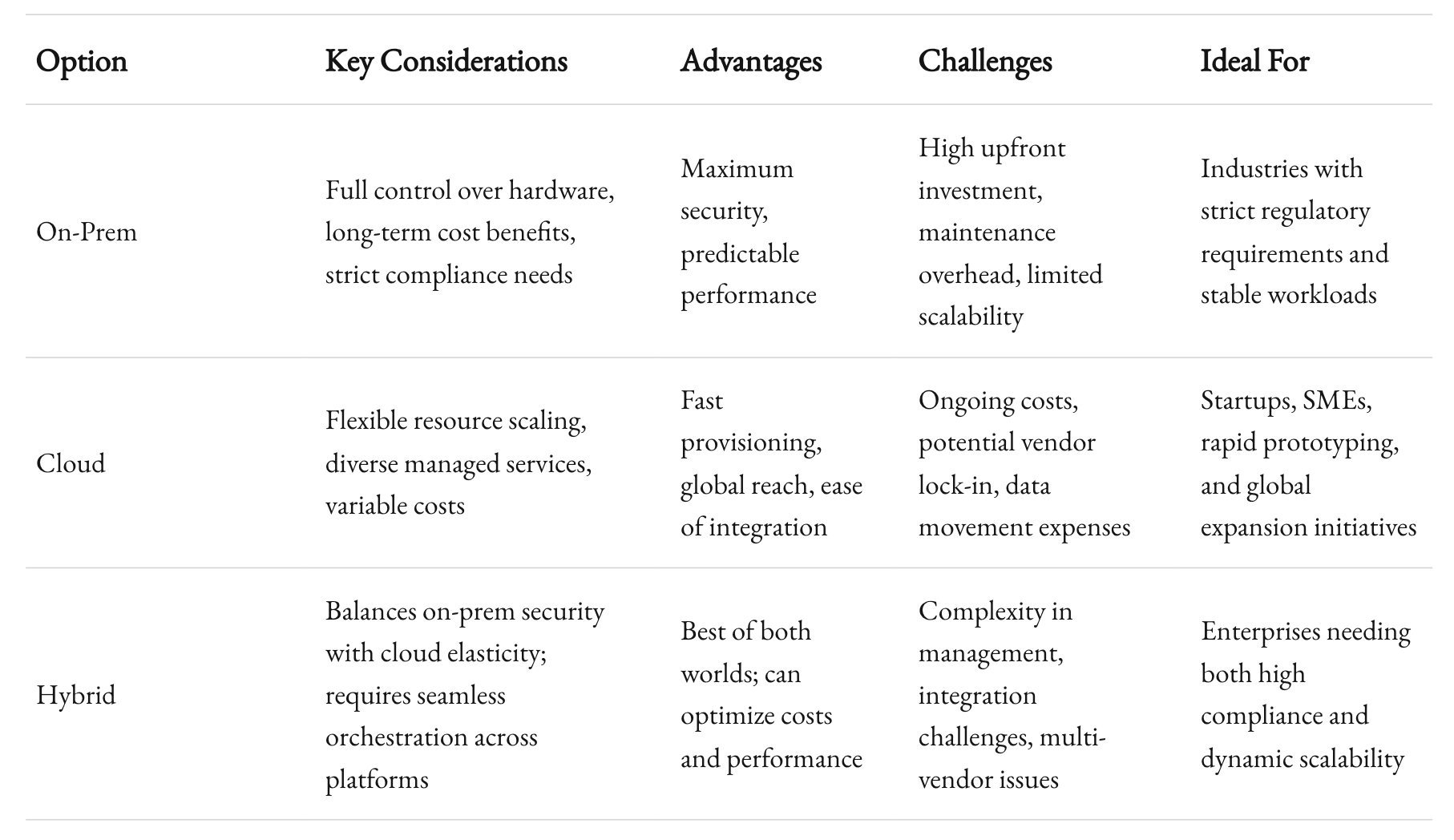
You’ve got options when it comes to where and how you run AI workloads. On-premise, cloud, or a hybrid approach. Specialized HPC clusters or fully managed platforms. Each has trade-offs. Below is a quick comparison table to highlight some of the core considerations.
Multi-Cloud vs. Single Cloud
A single-cloud strategy might be simpler to manage at first. But multi-cloud strategies can help you avoid vendor lock-in. Some organizations run inference on AWS while doing data processing on Azure, for instance. They pick the best tool for each job. The downside is complexity. Different clouds have different APIs, billing models, and security protocols. You’ll need strong orchestration to pull this off.
If you do go multi-cloud, think carefully about data gravity. Large datasets are expensive to move. You might not want to store 10 petabytes of data in two different clouds just for the sake of redundancy. Your data pipeline strategy should reflect how you plan to use that data. That might mean storing historical data in a cheap, cold-storage bucket in one cloud while processing smaller subsets in another.
Looking Ahead: Quantum and Beyond
It might sound futuristic, but companies like IBM, Google, and startups like Rigetti are pushing quantum computing forward. Quantum might not replace classical computing for every AI workload. However, certain optimization problems and large-scale linear algebra tasks could see improvements. If you’re building a truly future-proof stack, keep an eye on these developments.
The main takeaway: don’t invest all your capital in exotic hardware tomorrow. But do keep your architecture modular. Do keep track of evolving APIs that might allow quantum simulators or specialized quantum hardware to slot in. If quantum computing does prove game-changing for your specific domain, you’ll thank yourself for having an adaptable stack.
Implementation Details That Matter
Containerization and Microservices
If you’re not containerizing your AI workloads, you’re behind the curve. Docker provides an easy way to encapsulate your models, dependencies, and environment. Kubernetes lets you scale and orchestrate these containers. The microservices approach means you can separate data ingestion, feature engineering, and model inference into distinct services. Each service can scale independently. Each can be developed, tested, and deployed without interfering with the others.
This approach also means you can test out new frameworks or hardware options in a single microservice without changing your entire pipeline. Let’s say you want to try PyTorch 2.0 for a subset of your models while the rest run on TensorFlow. You can containerize PyTorch, deploy it on a single microservice, and keep the rest as-is. That’s a real example of future-proofing.
Observability and Monitoring
What happens after you deploy a model into production? You need real-time insights into performance, latency, and resource usage. This means integrating robust observability tools. Platforms like Prometheus, Grafana, and ELK (Elasticsearch, Logstash, Kibana) can help you collect metrics and logs at scale. For AI workloads, you’ll also want to track inference accuracy, confidence intervals, and user feedback. This data can inform your re-training schedules and help you catch anomalies early.
Monitoring also plays into cost control. AI workloads can skyrocket your cloud bills if left unchecked. A thorough monitoring setup alerts you when GPU usage spikes or if data pipelines are idling. This data can help you optimize resource allocation or spin down unused containers.
Security and Compliance
AI systems often deal with sensitive data. Medical records, financial transactions, personal user data. If you’re not locking down your stack, you’re risking more than just downtime. You’re risking brand reputation, regulatory fines, and legal trouble. Ensure every layer—from data ingestion to model storage—follows best practices. Encrypt data in transit and at rest. Use role-based access control (RBAC) to limit who can deploy new models.
For compliance, frameworks like SOC 2, ISO 27001, or HIPAA might apply, depending on your industry. If your AI stack isn’t designed with these in mind, you’ll face hurdles when scaling or pivoting. A future-proof strategy bakes security and compliance into the architecture from day one, not as an afterthought.
Building the Right Team
At 1985, we’ve found that many AI initiatives fail not because the technology isn’t there, but because the right people aren’t in place. For a future-proof AI stack, you need cross-functional expertise. Data engineers who know how to wrangle messy datasets at scale. ML engineers who understand model deployment intricacies. DevOps specialists skilled in CI/CD pipelines, container orchestration, and monitoring. And product managers who can tie it all back to real business needs.
Skill Sets That Matter
- Data Engineering: ETL/ELT best practices, data lake architectures, and streaming frameworks like Apache Kafka or Flink.
- ML Engineering: Familiarity with multiple frameworks (TensorFlow, PyTorch), distributed training paradigms (Horovod, PyTorch DDP), and model deployment patterns (serverless inference, microservices).
- MLOps/DevOps: Deep knowledge of Kubernetes, Terraform for infrastructure as code, model monitoring tools, and best practices for continuous integration and deployment.
- Security/Compliance: Expertise in data encryption, key management, role-based access control, and relevant industry regulations.
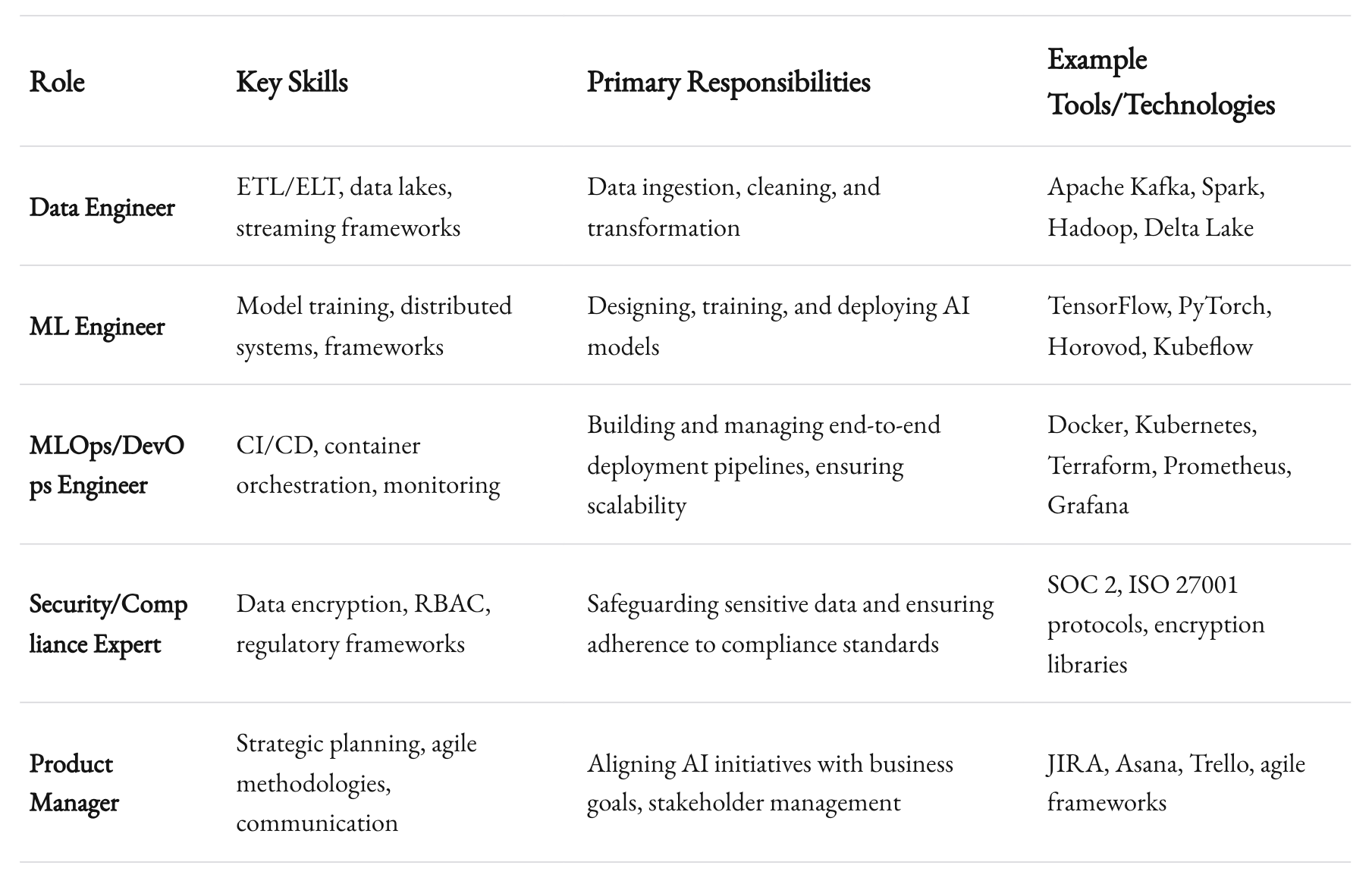
Building or partnering with a team that covers these bases keeps you prepared. You won’t have to scramble for specialists every time a new technology wave hits.
Balancing Full-Time Employees vs. Outsourcing
There’s a debate over how much of this AI effort should remain in-house versus outsourcing. At 1985, we’re obviously biased toward the outsourcing model when it makes sense. But the reality is you need a healthy blend. Keep strategic roles in-house—people who understand the core product and the company’s overarching strategy. Outsource or contract specific functions where specialized expertise is needed only occasionally.
For instance, if you’re trying to integrate a new HPC solution or test a specialized chip, you might not need a full-time HPC engineer on staff year-round. A specialized outsourced team can help you implement and hand off once everything’s stable. The key is to manage knowledge transfer well. Don’t let your outsourced partner become a silo of essential information. Documentation and training sessions help ensure your in-house team can maintain and evolve the system.
Measuring Success and Staying Adaptable
Key Metrics to Track
Future-proofing is an ongoing process. How do you measure whether your AI stack is on the right path? Look at these metrics:
- Model Performance Over Time: Accuracy, precision, recall—whatever’s relevant to your domain. Track how these metrics evolve with each iteration of data or each new model version.
- Deployment Frequency: How quickly can you push model updates to production? Faster deployments often mean more agility.
- Time to Recovery: When something breaks, how quickly can you fix it?
- Hardware Utilization: Are you paying for idle GPUs or wasting resources on redundant clusters? Keep a close eye on actual utilization.
- Data Quality Metrics: Levels of missing or corrupted data, outliers, or drift from training distributions.
Continuous Learning Culture
No matter how advanced your infrastructure, it won’t save you if your team stops learning. This field changes almost monthly. New frameworks, new chips, new research breakthroughs. A future-proof stack is always a moving target. Encourage ongoing education. Send your engineers to conferences like NeurIPS or re:Invent. Host internal “tech talks” where people share what they’ve learned. Experiment with proofs of concept on new technologies.
The AI race is partly about skill sets. If your talent remains curious and engaged, the technical side becomes easier. If your culture is stagnant, even the best hardware and software will eventually go to waste.
Recap
Staying future-proof in AI isn’t a one-time decision. It’s a continuous dance with evolving technology, shifting market demands, and new regulatory landscapes. I’ve seen clients who treat AI infrastructure like a static purchase order. They buy some servers, license a tool, and call it a day. In a year, they’re obsolete. In two years, they’re panicking. In three years, they’re shelling out big bucks to rebuild from scratch. That’s not the path you want.
Instead, build an AI stack that’s designed to flex with the future. Keep it modular. Embrace open standards. Invest in MLOps that help you track, monitor, and continuously update your models. Watch the hardware space closely—GPUs, TPUs, edge devices, or even quantum. Nurture a team with diverse skills who can pivot when change comes. And, above all, create a culture of learning. AI will keep changing, and so should you.
At 1985, we’re committed to this philosophy. We’ve learned the hard way that there are no shortcuts. But we’ve also seen the payoff when you get it right: stable, scalable, and adaptive AI systems that deliver lasting value. That’s the core of true future-proofing. It’s not about chasing every shiny object in the tech world. It’s about building with openness, resilience, and a dash of healthy skepticism.
I hope the insights here help you shape a strategy that stands the test of time. AI isn’t slowing down. The question is whether you’ll keep up. If you ask me, that depends on your infrastructure, your team, and your willingness to adapt. The future may be uncertain, but with the right approach, you can navigate it confidently—and maybe even define it for the rest of us.
Stay curious, and good luck on your AI journey!


