How Do We Ensure Our Software Can Handle Rapid User Growth?
Rapid user growth shouldn’t be a crisis—explore intelligent ways to prepare your software for scaling success.


You've launched your software, and it's gaining traction—quickly. Overnight, your user base balloons from a couple of hundred to thousands, maybe tens of thousands. Sounds like a dream, right? But unless you've prepared your software to handle that rapid growth, your dream can quickly spiral into a nightmare. Glitchy services, system crashes, and frustrated users all await you if you aren't ready to scale.
The journey from a promising prototype to a full-scale product is one filled with challenges. Yet, the thrill of seeing users flock to your software—engaging with it, trusting it—is unbeatable. As the founder of 1985, an Outsourced Software Development company, I've seen both sides of the growth spectrum: the elation of hitting a growth spurt and the panic of realizing the architecture can’t keep up. Today, we’ll dive into the how, why, and what to ensure that your software doesn’t just handle user growth—it thrives on it.
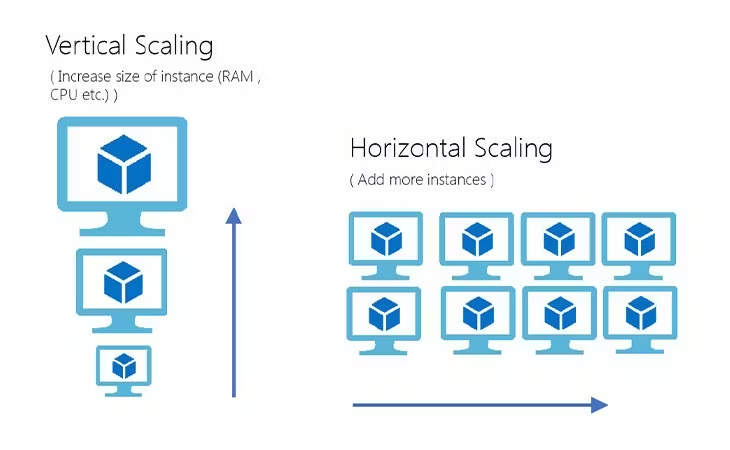
It’s Not Just About Adding More Servers
Scalability is one of those terms that gets tossed around a lot, especially in boardrooms and investor pitches. It’s a broad concept, but when we talk about software, scalability is the ability of a system to gracefully handle increased load. Sounds simple, right? But it's anything but simple. You can't just throw in more servers and expect everything to magically work—at least not efficiently or cost-effectively.
Scalability involves understanding how each part of your architecture interacts. It's about knowing where bottlenecks lie—like that database query that works fine with 100 users but becomes a nightmare at 10,000 users. It means having metrics that tell you where stress points are. And most importantly, it’s about designing systems that evolve as load increases. Every part of your system—from your backend logic to the databases, caching mechanisms, and network handling—plays a crucial role.
It's also about being proactive rather than reactive. So, instead of waiting for your server logs to light up like a Christmas tree during peak times, your system should be ready, willing, and able to tackle whatever the users throw at it. How do we do that? By diving deeper into some pinpointed strategies.
Design for Growth, Not Just Functionality
1. Start with a Modular Architecture
If there’s one takeaway from this post, let it be this: modularity is your best friend. It’s easier to scale parts of a system independently than to deal with a monolithic behemoth. A modular architecture splits your software into smaller, self-sufficient units that communicate through well-defined interfaces.
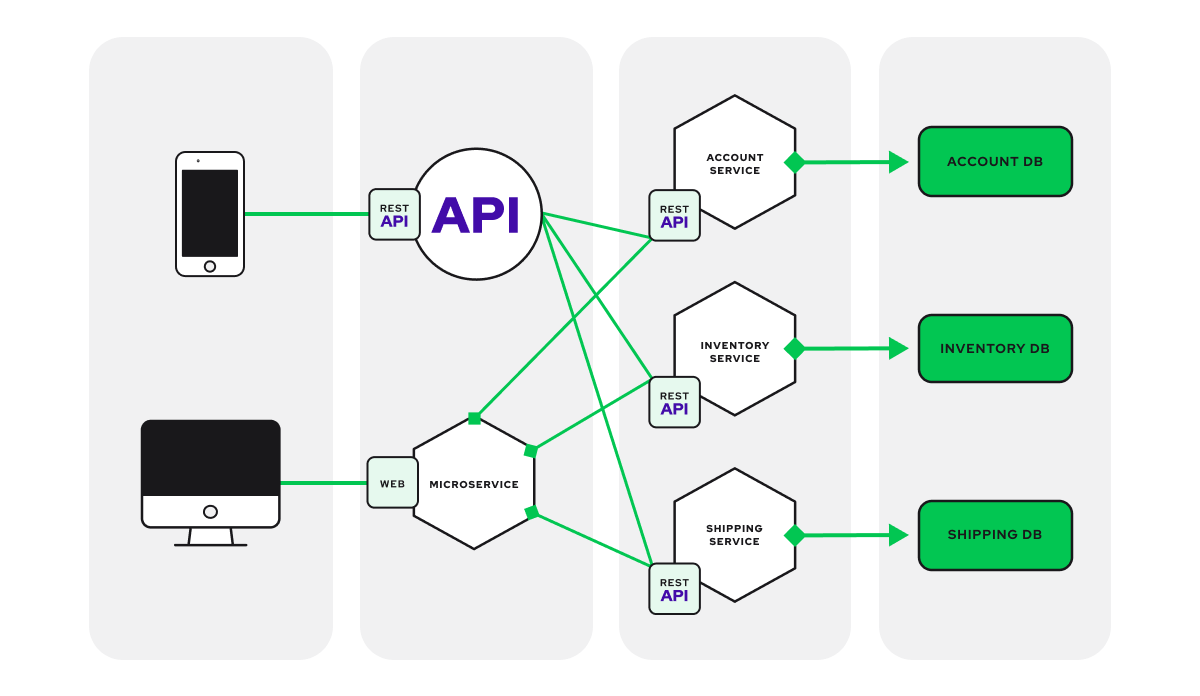
Think of this as the difference between upgrading a single room in a house versus tearing down and renovating an entire mansion. If one component—say, a payment service—experiences a surge, you can allocate more resources specifically to that module rather than wasting resources across the entire platform.
Microservices are an increasingly popular choice for scaling purposes. Each service—such as user management, inventory, or analytics—is separate and operates independently. This setup not only helps with scaling, but also makes your architecture more resilient to failure. If one service goes down, the others keep humming along.
At 1985, we once helped scale a financial services platform where user analytics was the heaviest hitter. We isolated that component, implemented a separate instance for it, and could tune and scale independently of other parts of the system. This isolation led to an 80% reduction in outages during high-traffic periods. The key here is to plan for modularity early; bolting it on later is far more complex.
2. Load Balancing and Horizontal Scaling
When your users multiply, you need to multiply your capacity as well. This is where load balancing comes in. Instead of depending on a single server, a load balancer distributes traffic across multiple servers to ensure no single server becomes a bottleneck.
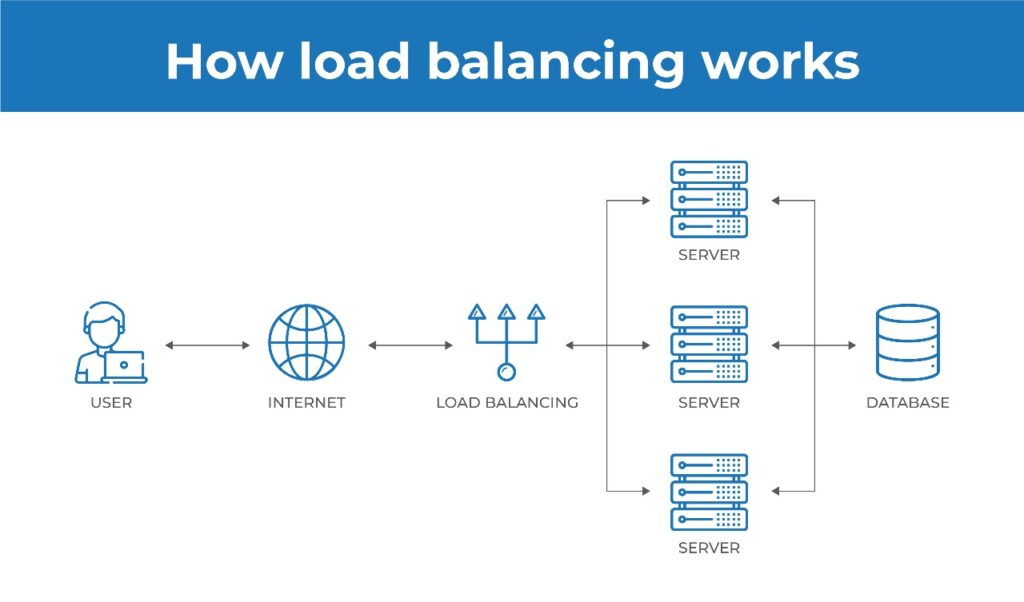
Horizontal scaling—where you add more servers instead of upgrading existing ones—is a go-to strategy in these scenarios. Amazon, Netflix, and every other company dealing with millions of users rely on load balancing and horizontal scaling.
Let’s be clear: configuring a load balancer isn’t simply about increasing server count. There’s fine-tuning involved. Sticky sessions, where a user’s session stays on one server, caching policies, and health monitoring are a few elements that can make or break your load balancing setup. Without intelligent distribution, users will still end up facing service outages, which defeats the whole purpose of scalability.
Employing Databases to Handle Growth
3. Rethink Your Database Strategy
If you're running your database with a traditional setup—think one central RDBMS—there will come a day when it's the reason your entire system crawls to a halt. Scalability in databases is a beast of its own, requiring careful planning.
Vertical vs. Horizontal Database Scaling
- Vertical Scaling: Adding more resources (CPU, RAM) to a single machine. This works up to a point but has a ceiling.
- Horizontal Scaling: Distributing data across multiple machines using methods like sharding, replication, or partitioning.
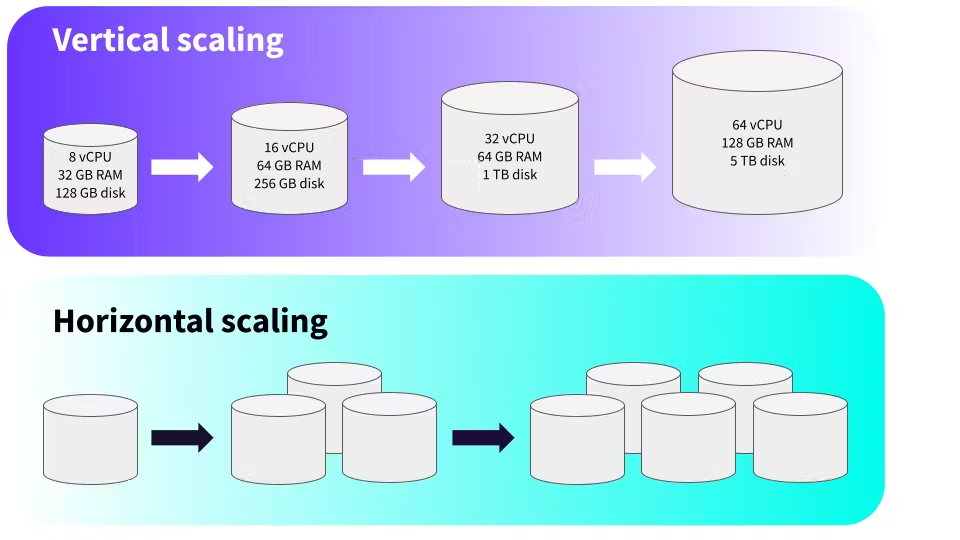
Sharding splits your data into distinct groups, so not every query hits the entire dataset. Replication allows read-heavy systems to thrive by providing multiple read-replicas. Think of replication like having different toll gates for cars—vehicles are distributed across different lanes, reducing the load on a single one.
At 1985, we worked with an e-commerce startup that faced growing pains when user numbers shot up. By rethinking the database architecture and implementing sharding strategies, we reduced query times by over 50%, even during peak sales periods.
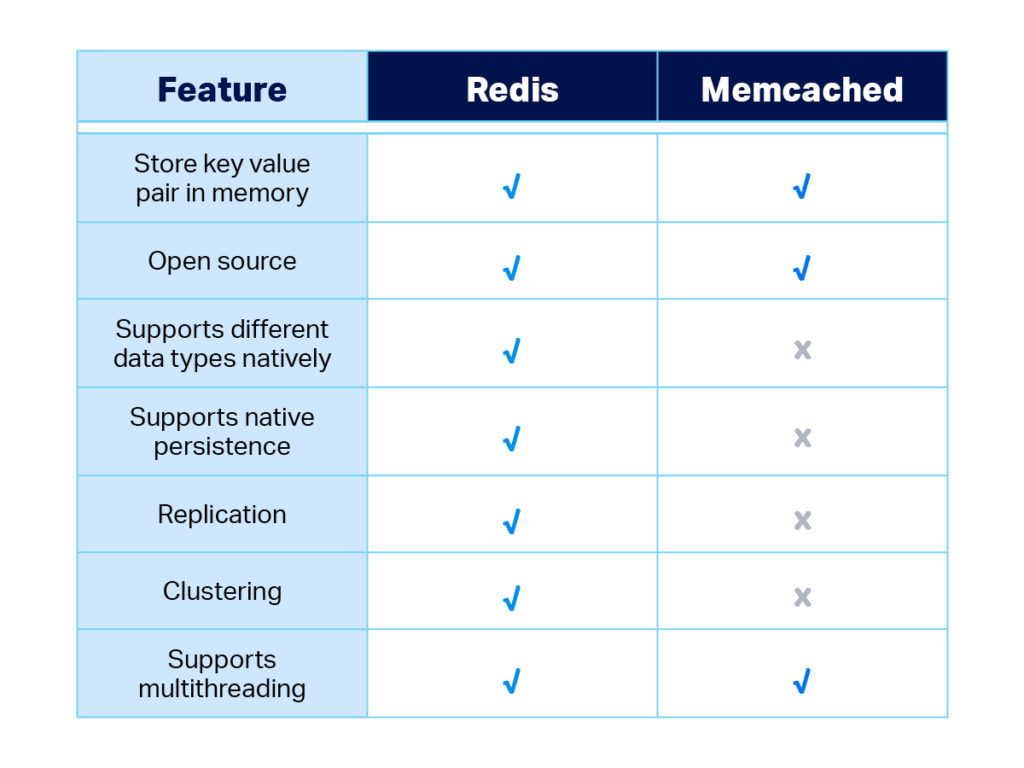
4. Use Caching Effectively
Caching is an absolute game-changer for scaling. Repeated queries—like fetching user profiles or frequently accessed product lists—can be cached, significantly reducing load on the database. When employed smartly, caching can prevent your database from turning into a bottleneck during peak traffic.
Consider tools like Redis or Memcached. For many, Redis acts as an in-memory store for all frequent requests, which might otherwise go to the database. This cuts latency and ensures users get what they need—fast.
Imagine a social media platform—without caching, every refresh means querying for a user’s posts, likes, and followers from scratch. The load quickly becomes unbearable. With caching, that repeated data is stored and easily accessed, making the experience seamless.
Handling Concurrency and Traffic Spikes
5. Employ Asynchronous Processing
Concurrency can be your enemy if you’re not prepared. If every user's request happens in a synchronous manner, the entire process slows down. Introducing queues and asynchronous processing helps deal with spikes in real-time traffic.
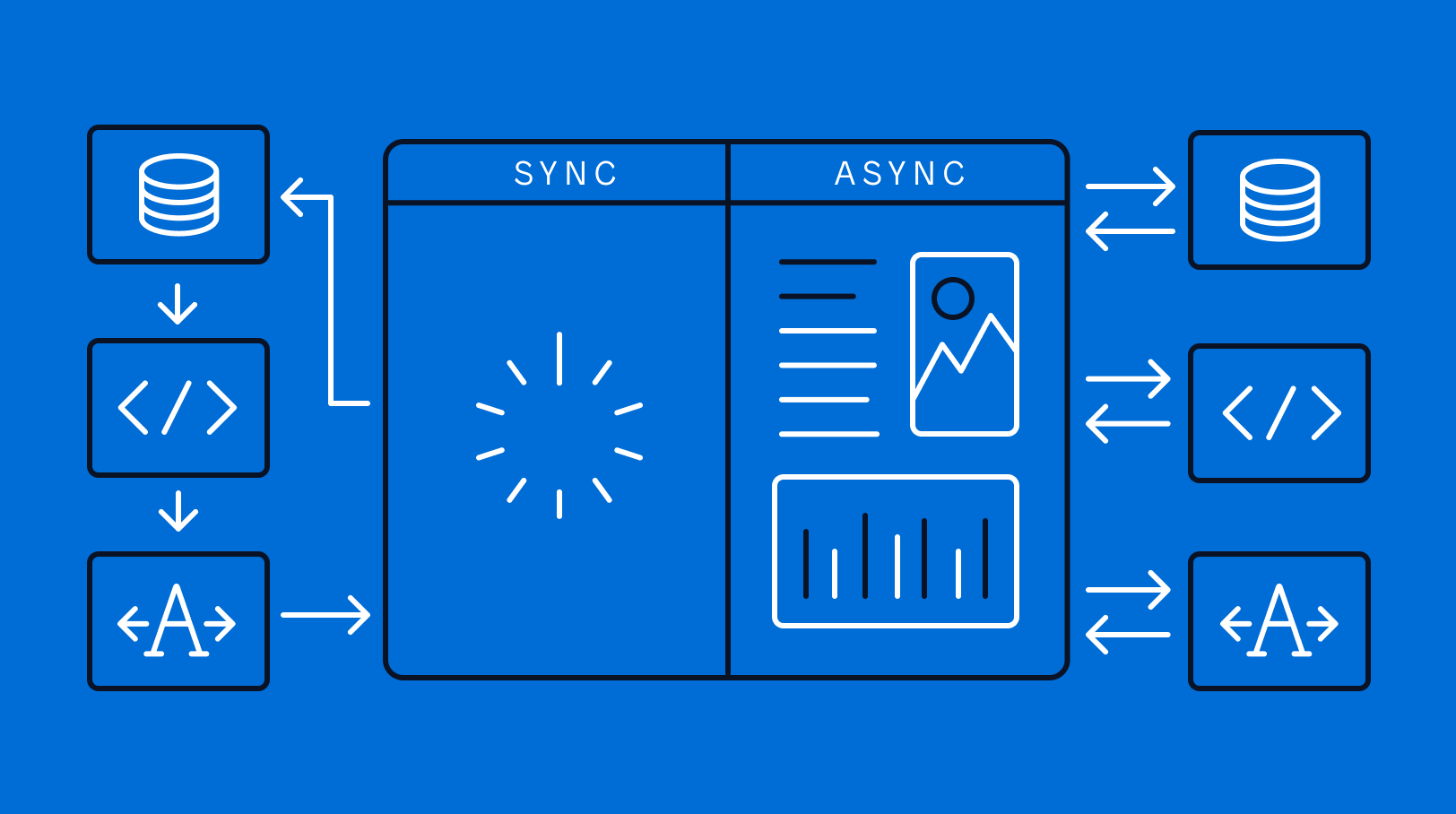
Queues, like those offered by RabbitMQ or Kafka, store incoming requests and process them as resources become available. You don’t need everything to happen in real time—at least not always. Background jobs are your best friend in this area, allowing your main threads to remain responsive while pushing less critical processes to the background.
For example, when sending an email confirmation to a user, there’s no reason to hold up their experience while your server tries to send the email. Throw it into a queue. Let it happen asynchronously. Keep the experience fluid.
At 1985, we saw a massive improvement in system responsiveness when we decoupled certain processes and made them asynchronous. For a client in the healthcare industry, simply queuing non-critical tasks reduced user complaints about system lag by 40%.
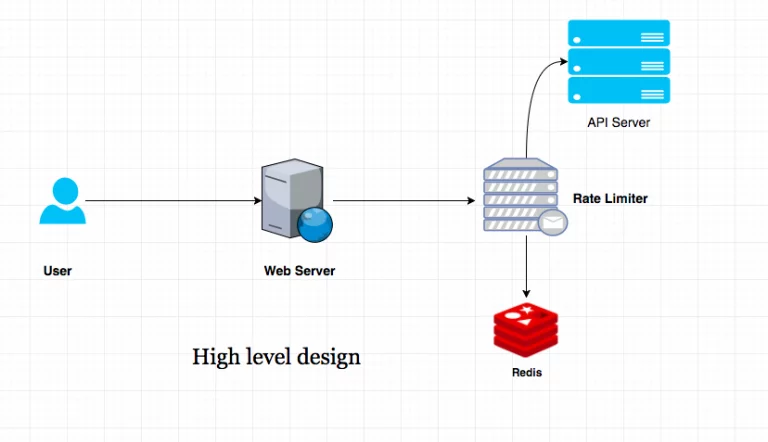
6. Rate Limiting and Graceful Degradation
Even with the best-laid scaling plans, sometimes demand just overshoots your resources. In these situations, rate limiting comes to the rescue. Rate limiting ensures that no single user can overwhelm your system with too many requests. API rate limits are crucial, especially when dealing with external integrations.
Graceful degradation is about maintaining some form of functionality when parts of your system are under heavy load. Think of it as an emergency generator. Instead of crashing completely, a social media site might choose to load core feeds but disable comments until things stabilize. Netflix, for example, might temporarily reduce video quality during massive demand spikes.
Monitoring and Alerting: The Unsung Heroes
7. Real-Time Monitoring is Non-Negotiable
“You can’t manage what you can’t measure.” This mantra is especially true for software scalability. Monitoring tools like Prometheus, Grafana, or Datadog help you see exactly what's happening at all times.
Set up real-time alerts. If your CPU utilization is creeping above 80%, you should know about it before it hits 100% and starts failing. If your database query times suddenly spike, someone should be on it immediately. Use New Relic or AppDynamics for application performance monitoring, giving you insights into response times, database queries, and potential bottlenecks.
At 1985, we recommend having dashboards set up that display key system health indicators—things like memory usage, database performance, and network throughput. The beauty of this is that you stop firefighting and start proactive management. Scaling becomes less of a guessing game.
8. Autoscaling: Preparing for Spikes and Surprises
Autoscaling is the ability of your infrastructure to expand or shrink automatically based on predefined metrics. AWS Auto Scaling and Azure Autoscale are industry standards that enable your application to grow when a traffic spike hits, and scale back down during quieter periods.
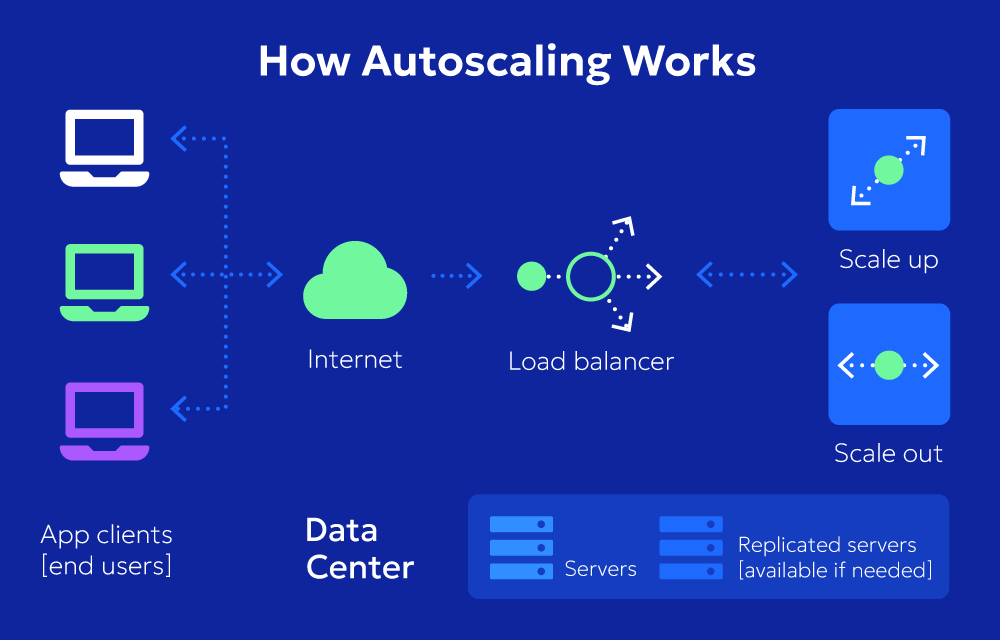
This is ideal for apps with unpredictable user growth or seasonal peaks. Picture an e-commerce platform during Black Friday. Without autoscaling, you’re either paying too much year-round for extra resources or running out of capacity when it counts. Autoscaling provides flexibility, ensuring you maintain performance while keeping costs under control.
Team Collaboration and Cultural Readiness
9. DevOps Practices: Build with Operations in Mind
Scalability isn't just about technology—it’s also about culture. DevOps brings development and operations teams closer together, meaning issues are tackled collaboratively and with a holistic perspective. From continuous integration and continuous deployment (CI/CD) pipelines to regular load tests, a DevOps culture means you're always aware of your software’s operational state.
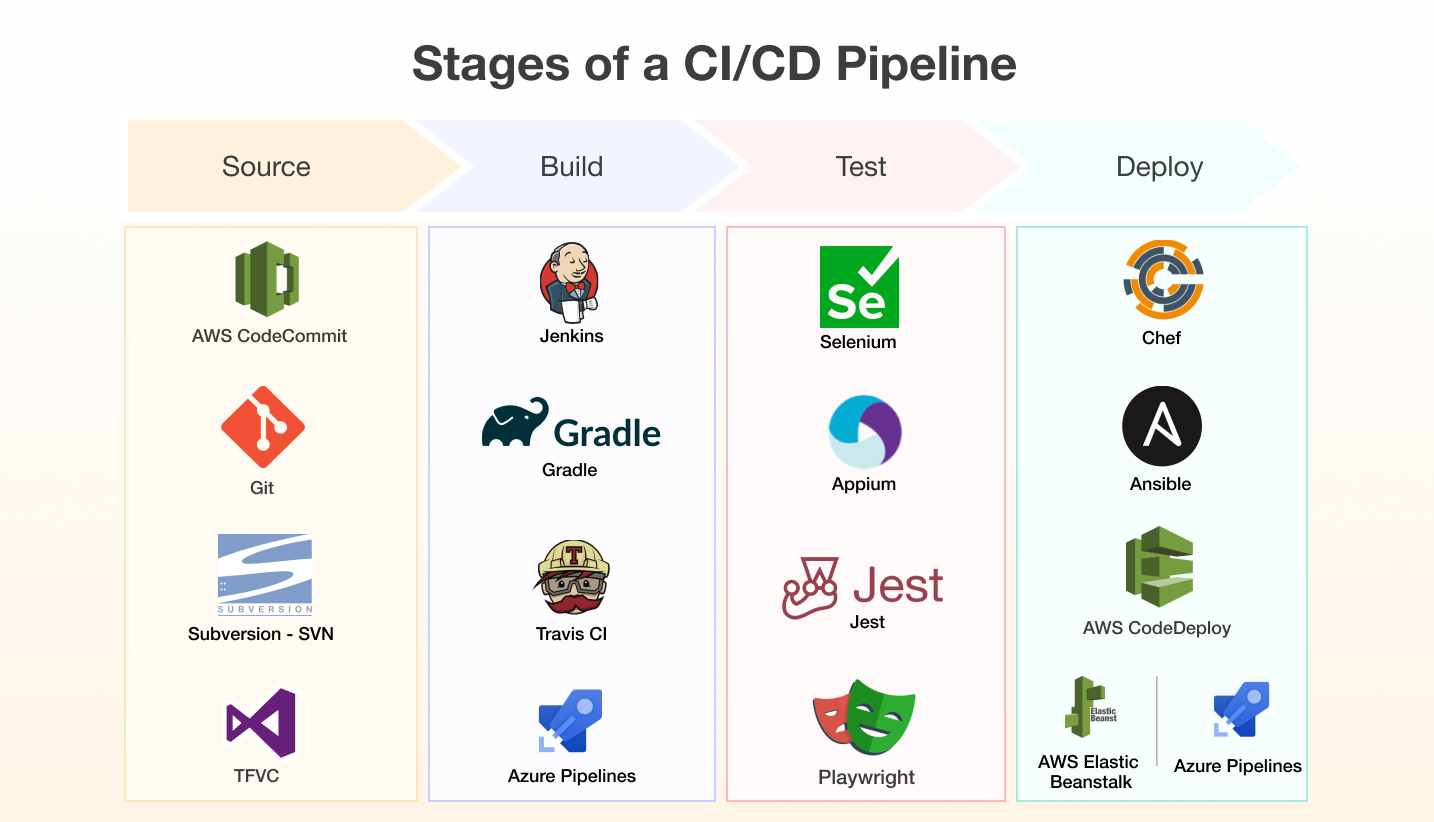
At 1985, we instill DevOps practices in our projects from the outset. Deployments become more seamless, infrastructure as code (IaC) ensures reproducibility, and potential scaling issues are discussed early, not when the ceiling’s about to collapse.
10. Have a Rollback Plan
We all love the idea of perfect software, but let’s face it—deployments sometimes fail. Have a rollback plan in place. Rollbacks should be automated as much as possible, allowing you to revert to the previous version if a new deployment doesn’t work as expected under increased load.
Netflix’s culture of Chaos Engineering emphasizes resilience by regularly simulating failures. They’re prepared for issues, and when things go wrong, there’s already a battle-tested plan in place. You don’t need a huge engineering budget to do the same—automated snapshots, backups, and rollback scripts can all go a long way.
Making Scalability a Mindset
Scaling software isn’t a set-it-and-forget-it task. It requires ongoing commitment, constant iteration, and the ability to look at the big picture while never ignoring the small, technical details. To handle rapid user growth, you need to be a bit like a chess player—always thinking a few moves ahead.
To summarize, building scalable software requires a solid foundation: modular architecture, efficient databases, smart load balancing, and cultural readiness. It's not just about surviving user growth; it's about delivering a great user experience, regardless of how many people are using your software at a given moment.
Your users don’t care about the technical details. They want a seamless experience—fast response times, no crashes, no outages. By embracing these strategies, you’re ensuring that the next time growth knocks at your door, you’re more than ready to let it in.
Remember, growth is a journey, and at 1985, we love the challenge of making that journey a little smoother, a little more exciting, and a lot more scalable.


