How Do We Balance Innovation with Maintaining Stable, Reliable Systems?
How to innovate fearlessly while keeping your systems stable and reliable—an intelligent approach for modern tech teams.


Innovation is intoxicating. It's what gives our industry its edge. It excites developers, brings new possibilities to the fore, and changes the rules of the game. But, while we chase innovation like a cat after a laser pointer, there's something else that keeps us grounded—stability. Without it, we risk tearing apart everything we've built, sacrificing reliability for something shiny and new.
At 1985, where we help businesses build the tech they need, we've seen this tension up close. Companies want innovation, but they also want systems that won't crash during a product launch or a Black Friday sale. They want speed, and they want security. They want new features, and they want something that just works, day in and day out.
So, how do we keep the scales balanced? How do we avoid the pitfalls of moving too fast and breaking things, without being paralyzed by our fears of something breaking? This balancing act is at the heart of what we do as tech leaders, architects, and developers. Let's dive into the nuanced reality of how to navigate this challenging but crucial trade-off.

The Anatomy of the Innovation vs. Stability Trade-off
It's easy to romanticize innovation. We love the startup story—the audacious founders creating something revolutionary, disrupting a stagnant industry. But behind the scenes, for every feature update and technological leap, there's a risk calculus at play.

On one hand, you have the potential rewards: greater efficiencies, happier customers, new revenue opportunities. On the other, there are the risks: downtime, security breaches, and broken user experiences. No company wants to be in the headlines for the wrong reasons—whether it's a catastrophic service outage or a security vulnerability exploited by hackers.
Consider Amazon's famed "two-pizza teams," where each team can be fed by two pizzas and works with autonomy to innovate. What’s less celebrated is the rigor in Amazon's internal systems—the monitoring, testing, and redundancy that helps keep their vast ecosystem stable. They push the envelope but are equally obsessed with making sure the envelope doesn't tear at the seams.
This is not an easy line to walk. It requires not just a careful choice of tools and methodologies but also a cultural mindset that values both creativity and consistency. The very essence of technology leadership is to find equilibrium in this equation.

Why Innovation Sometimes Feels Like the Enemy of Stability
There's an adage: "If it ain't broke, don't fix it." In the tech world, this often clashes with our impulse to tinker, improve, and outdo our past selves. But what happens when the desire to innovate introduces unintended side effects?
I've seen this firsthand at 1985. A client wanted to overhaul their back-office system—a legacy beast held together by what felt like duct tape and sheer willpower. The new architecture promised microservices, scalability, and a decoupled dream. But halfway through the transformation, we started seeing gaps—in the integration of microservices, in testing strategies, in data consistency. It turned out, breaking the monolith also broke certain assumptions about data integrity that were baked into the old system.
Sometimes, stability suffers because innovation looks so darn appealing. The promise of moving away from legacy monoliths or adopting the latest NoSQL database can make teams forget why things were done a certain way to begin with. The old system may be clunky, but it's predictable. In the pursuit of innovation, we risk losing that predictability, exposing us to issues we never had before.
However, stagnation is not an option either. Markets evolve, customer expectations shift, and competitors move ahead. While legacy systems may provide reliability, they can also become a weight dragging down your company's ability to respond to change. That's why balancing these two forces is not just about saying "no" to innovation; it's about saying "yes, but wisely."
Building a Culture That Values Both
One of the most underrated ways to balance innovation and stability is through culture. It’s not just about practices and protocols but about shared values across your team. When teams align around a mission that emphasizes both moving fast and keeping the lights on, the balance comes more naturally.

1. Operational Excellence
Operational excellence isn't the antithesis of creativity. It’s the fuel for it. Teams that are diligent about documentation, playbooks, and observability are also the ones that can confidently experiment because they have safety nets in place. Netflix is a great example of a company that pushes boundaries while ensuring stability. Their "Simian Army" (tools that randomly cause outages and chaos) is designed to make sure stability isn’t an afterthought. Engineers at Netflix know their systems are resilient because they actively test them under duress.
At 1985, we prioritize operational readiness. When we roll out a new feature for a client, we also build rollback mechanisms and clear fallback paths. The idea is simple: innovate, but be ready to backtrack if things go wrong. This approach encourages our developers to try new things without the fear that one mistake will crash an entire system.
2. Shifting Left with Quality
The concept of shifting left—moving testing earlier into the development cycle—is not new, but it is critical in maintaining stability while innovating. When teams integrate testing, security checks, and performance assessments into the build process, it changes the dynamics.
Imagine developing a feature that requires a new API. If you're only testing it in a production-like environment days before launch, you're far more likely to introduce regressions or integration issues. But if you bring in testers, security experts, and even ops teams during the design phase, you catch the ripple effects before they grow into tsunamis.
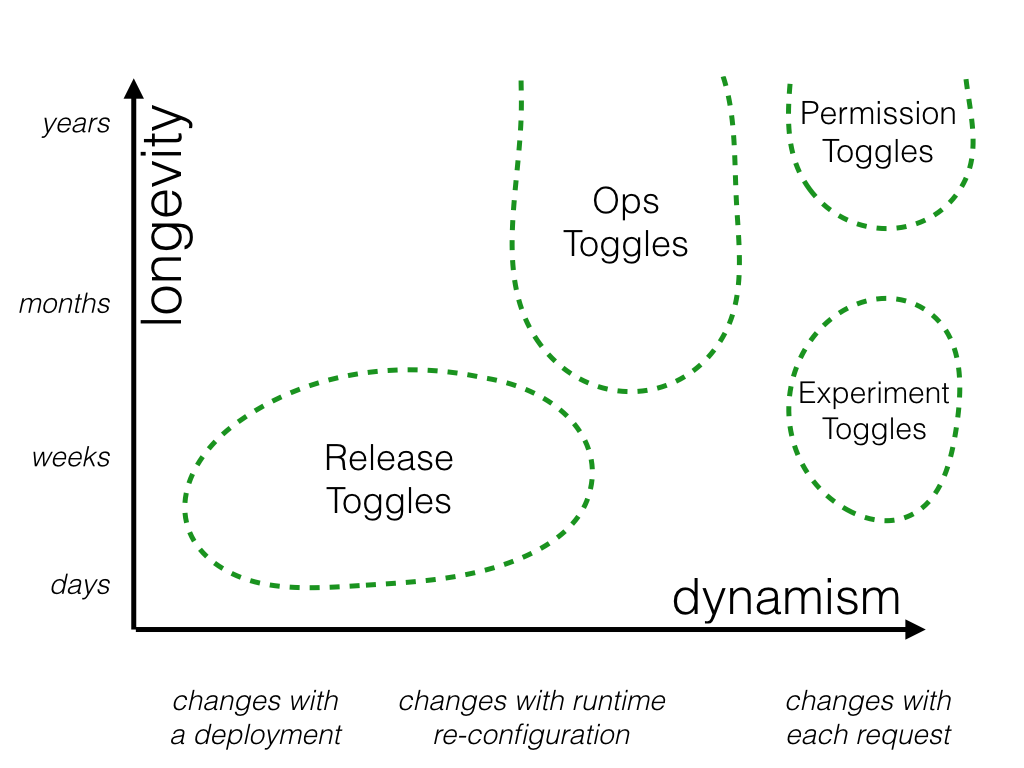
3. Feature Flags and Controlled Rollouts
Not everything needs to launch at once. Feature flags—the ability to turn features on or off—can be a great ally. They allow us to decouple deployment from release, providing control over how changes are introduced to users. For instance, you could release a new payment flow to just 1% of your user base and monitor how the change impacts their behavior or whether it causes unexpected errors.
We use feature flags liberally at 1985 to validate innovations in controlled environments before unleashing them to everyone. This incrementalism isn't a brake on innovation—it's a pragmatic way to innovate with stability as the co-pilot.
Technological Guardrails
Technical debt is inevitable. Some debt is intentional, incurred to get to market faster. Other forms, however, are a ticking time bomb—built-up workarounds and hacks that can erode system stability. To balance innovation and reliability, we need guardrails that help us manage, pay down, and even prevent technical debt.

1. Automated Testing and CI/CD
Automated testing has become the bedrock of stable innovation. Unit tests, integration tests, and end-to-end tests help ensure that new code plays nicely with the existing ecosystem. However, tests are only as good as the scenarios they account for. In our experience, having a dedicated "devil's advocate" on a team—someone tasked with thinking up bizarre use cases—helps strengthen automated testing.
Continuous Integration and Continuous Deployment (CI/CD) practices further help keep the balance. By integrating code early and often, issues are caught before they snowball into catastrophic failures. At 1985, our CI/CD pipelines enforce testing as a gate to progression. If a build doesn’t pass muster, it doesn’t move forward—simple as that.
2. Observability and Monitoring
Stability is about being proactive, not reactive. Observability tools help create systems where we know what's happening internally, often before a problem is visible to end-users. Metrics, logging, and distributed tracing give us insight into the health of our systems.
For instance, when one of our clients faced erratic spikes in traffic, the monitoring tools we had integrated—coupled with intelligent alerting—helped us zero in on a resource exhaustion issue. We managed to fix it before it escalated. Observability is what gives you confidence in pushing boundaries, knowing that if something fails, you'll be the first to know, and more importantly, you’ll know why.
3. Architectural Patterns for Resilience
Microservices, if done right, are fantastic for iterating quickly without compromising stability. The idea is to compartmentalize innovation—test a new feature in one microservice without risking the rest of the system. But they’re also harder to get right. For every benefit—scaling independently, decoupling teams—there's a corresponding challenge in maintaining consistency, managing API contracts, or handling distributed failure.
The strangler fig pattern is another architectural approach we’ve found useful at 1985, especially for clients with large legacy systems. Rather than tearing everything down to start anew, you incrementally build new features around the edges of an old system, slowly "strangling" it until the legacy part can be retired. It’s innovation that doesn’t bulldoze the reliability built over years.
Processes that Support Both Innovation and Reliability
The human side of the equation is often just as complex as the technical one. It’s easy to blame failures on poorly written code, but often, the root cause is poor communication, unclear ownership, or a lack of process.

1. Blameless Postmortems
Incidents will happen. What defines an organization’s maturity isn’t whether or not it encounters problems, but how it responds to them. Blameless postmortems are powerful tools for learning from failures without finger-pointing. By focusing on the process rather than the person, teams are more willing to take risks, knowing that they won’t be vilified if something goes wrong.
At 1985, we try to create an environment where every incident is treated as a learning opportunity—not just for the immediate team, but across the organization. Lessons learned from a failed release may prevent a similar issue for another team months down the line.
2. Cross-Functional Collaboration
Innovation is often siloed. Dev teams work on building features, Ops teams ensure uptime, and sometimes they barely interact. That’s a recipe for chaos when new changes go live. Bridging this gap with Site Reliability Engineering (SRE) practices or a "You build it, you run it" culture has proven effective for many.
Cross-functional teams—developers, QA, ops, and even product—should work together from the inception of a project. It’s something we enforce at 1985: innovation is everyone’s business, but so is stability. When product managers understand the nuances of technical debt, and when developers understand customer pain points, the solutions they build reflect both perspectives.
3. Risk Management Frameworks
Every new feature comes with a degree of risk. Establishing a risk management framework helps teams evaluate what could go wrong and, more importantly, whether the risk is worth taking. Think of it as a checklist of things to ask before pushing the big green button.
For instance, at 1985, we often ask:
- How easy is it to roll back?
- Are users being onboarded in stages, and can we control exposure?
- Have we stress-tested key functionalities?
- Are we aware of dependencies that could break?
These questions might seem pedantic, but they’re what make the difference between smooth sailing and scrambling to fix something after a fire breaks out.
Balancing Act in Practice: What We’ve Learned
Balancing innovation with stability is not just a technical challenge—it’s cultural, procedural, and deeply human. It’s about cultivating curiosity, but also responsibility. It’s about encouraging developers to innovate fearlessly, but equipping them with the right safety nets to do so responsibly.
We've learned at 1985 that this balance is not static. What worked last year may not work today. New tech paradigms emerge, user expectations evolve, and the competitive landscape shifts. That’s why we need both the discipline to maintain what's working and the audacity to reach for what's next.
Sometimes, the best thing you can do to stay innovative is to invest in stability. The better your foundation, the higher you can build—without the fear of it all coming crashing down.
Finding Your Own Balance
Every company has to chart its own path. The balance between innovation and stability is deeply contextual, and the "right" approach depends on your users, your team, and your market. But some principles are universal: value stability as much as innovation, invest in culture and collaboration, and create technological guardrails that let your team experiment without fear.
At 1985, we think of it as building not just for today, but also for tomorrow’s possibilities. It’s about giving yourself room to fail, but also the tools to ensure failure is a bump in the road, not a complete derailment. And above all, it’s about remembering that the real magic lies in balancing these forces—that only by keeping one foot firmly in the known can we confidently step into the unknown.


