Building a Scalable Tech Infrastructure from the Ground Up: A Founder's Perspective
Future-proof your startup: A no-nonsense guide to scalable tech architecture from a battle-tested founder.


The ability to scale quickly and efficiently can make or break a company. As someone who's been in the trenches, building software solutions for over a decade, I've seen firsthand how crucial it is to lay the right foundation from day one. Let's dive into the nitty-gritty of building a scalable tech infrastructure that can grow with your business, without causing sleepless nights and frantic firefighting down the road.
Think Big from Day One
When we founded our company, we made a conscious decision to think big from the start. It's tempting to cut corners in the early days, especially when you're racing against the clock and burning through your seed funding. But trust me, those shortcuts can come back to haunt you.
I remember a client, let's call them StartupX, who came to us in a panic. They'd built their initial product on a monolithic architecture, using a simple LAMP stack. It worked great for their first 10,000 users. But when they hit the jackpot with a viral marketing campaign and suddenly had 100,000 users hammering their servers, everything came crashing down. They lost potential customers and, more importantly, credibility.
The lesson? Even if you're starting small, architect your system as if you're building for millions of users. It might seem like overkill at first, but it'll save you massive headaches down the line.
The Building Blocks of Scalability
One of the most powerful approaches to building a scalable infrastructure is embracing microservices architecture. Instead of building one massive, monolithic application, you break your system down into smaller, independent services that communicate with each other.
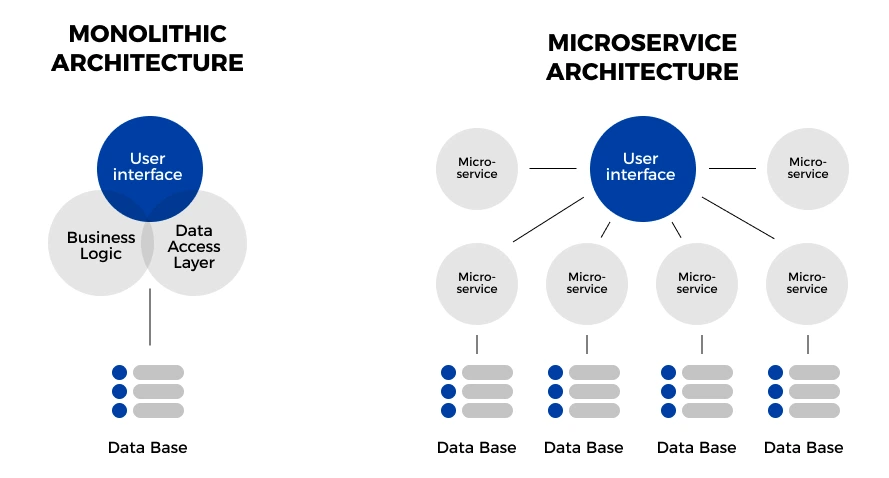
Let me give you a real-world example. We worked with an e-commerce platform that started with a traditional monolithic architecture. As they grew, adding new features became increasingly complex and risky. Every change, no matter how small, required testing the entire system. Deployments were nerve-wracking affairs that often stretched into the wee hours of the morning.
We helped them transition to a microservices architecture, breaking their application into discrete services: user authentication, product catalog, order processing, inventory management, and so on. The result? They could now update and scale each component independently. When Black Friday hit and their order processing service was under heavy load, they could quickly spin up additional instances of just that service, without touching the rest of the system.
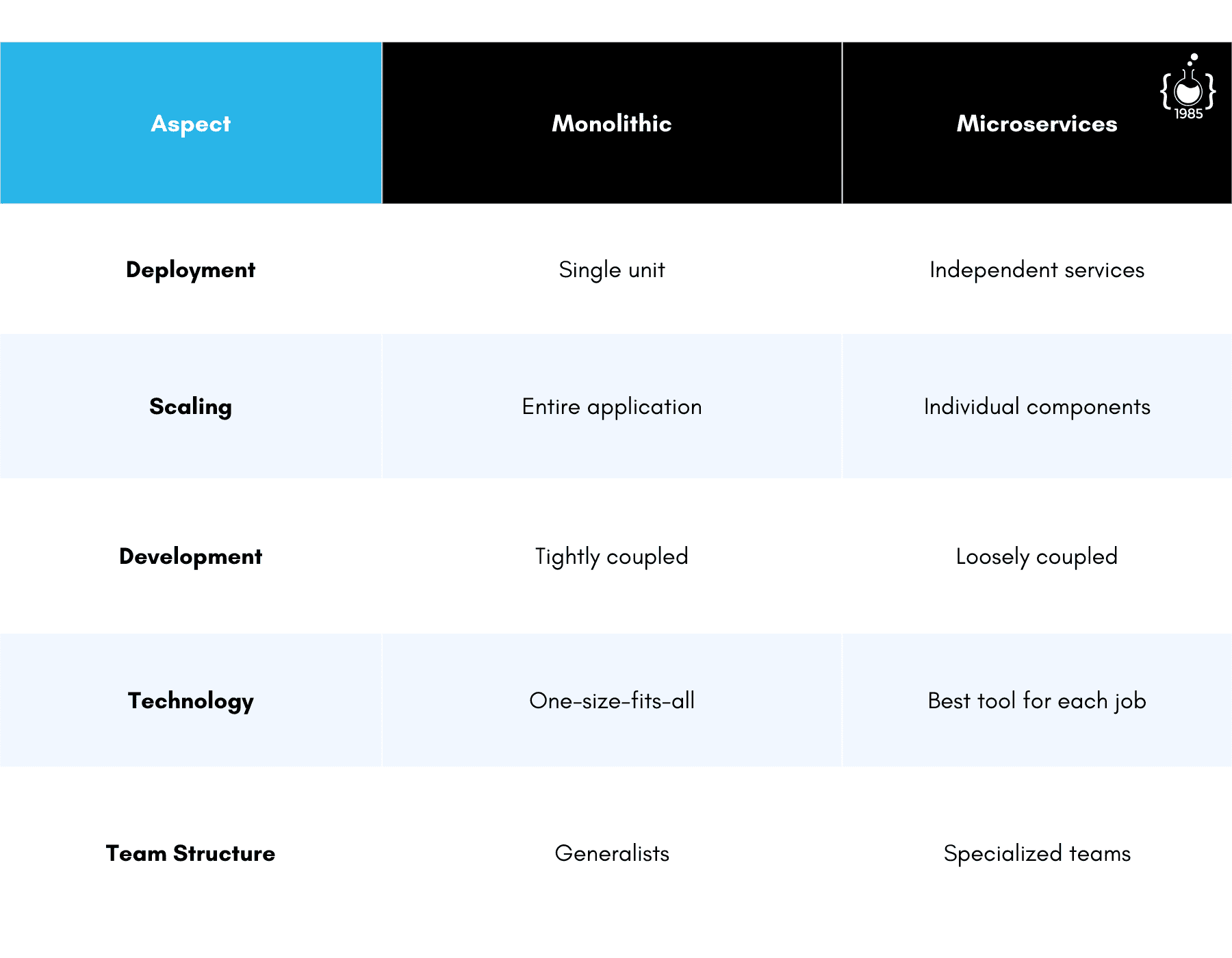
Here's a simplified comparison of monolithic vs. microservices architecture:
Containerization
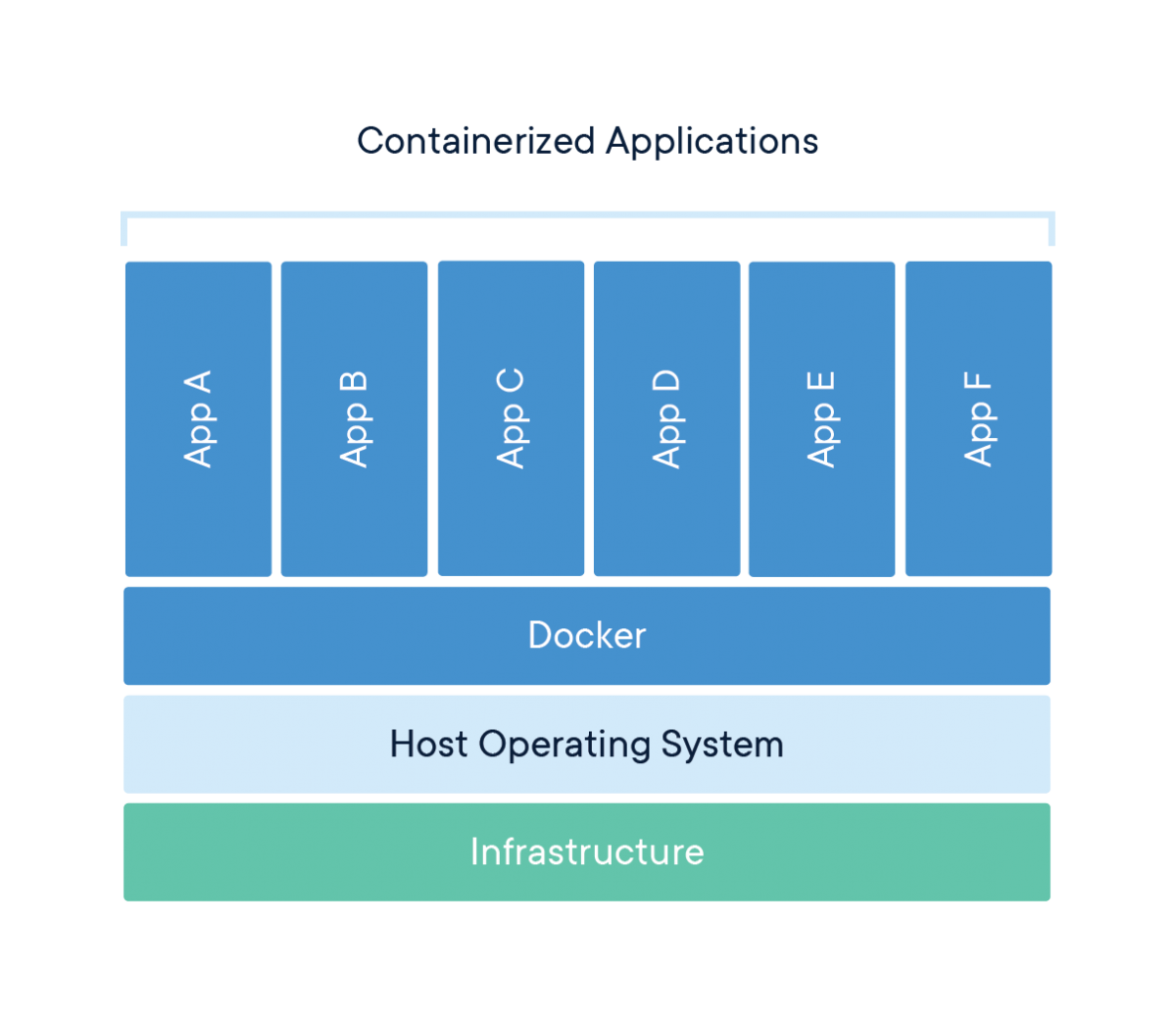
Hand in hand with microservices comes containerization. Docker has revolutionized how we package and deploy applications, and for good reason. Containers ensure that your application runs the same way, regardless of the environment – be it a developer's laptop, a test server, or your production cloud infrastructure.
I recall a particularly painful deployment we had in the early days of our company. We'd spent weeks developing a new feature, and everything worked perfectly in our development environment. But when we pushed to production, all hell broke loose. It turned out that our production servers were running a slightly different version of a key dependency. The ensuing scramble to debug and fix the issue in real-time was not an experience I'd wish on anyone.
Containerization eliminates these "it works on my machine" scenarios. By packaging your application and all its dependencies into containers, you ensure consistency across all environments. This not only makes deployments smoother but also significantly speeds up your development and testing cycles.
The Cloud
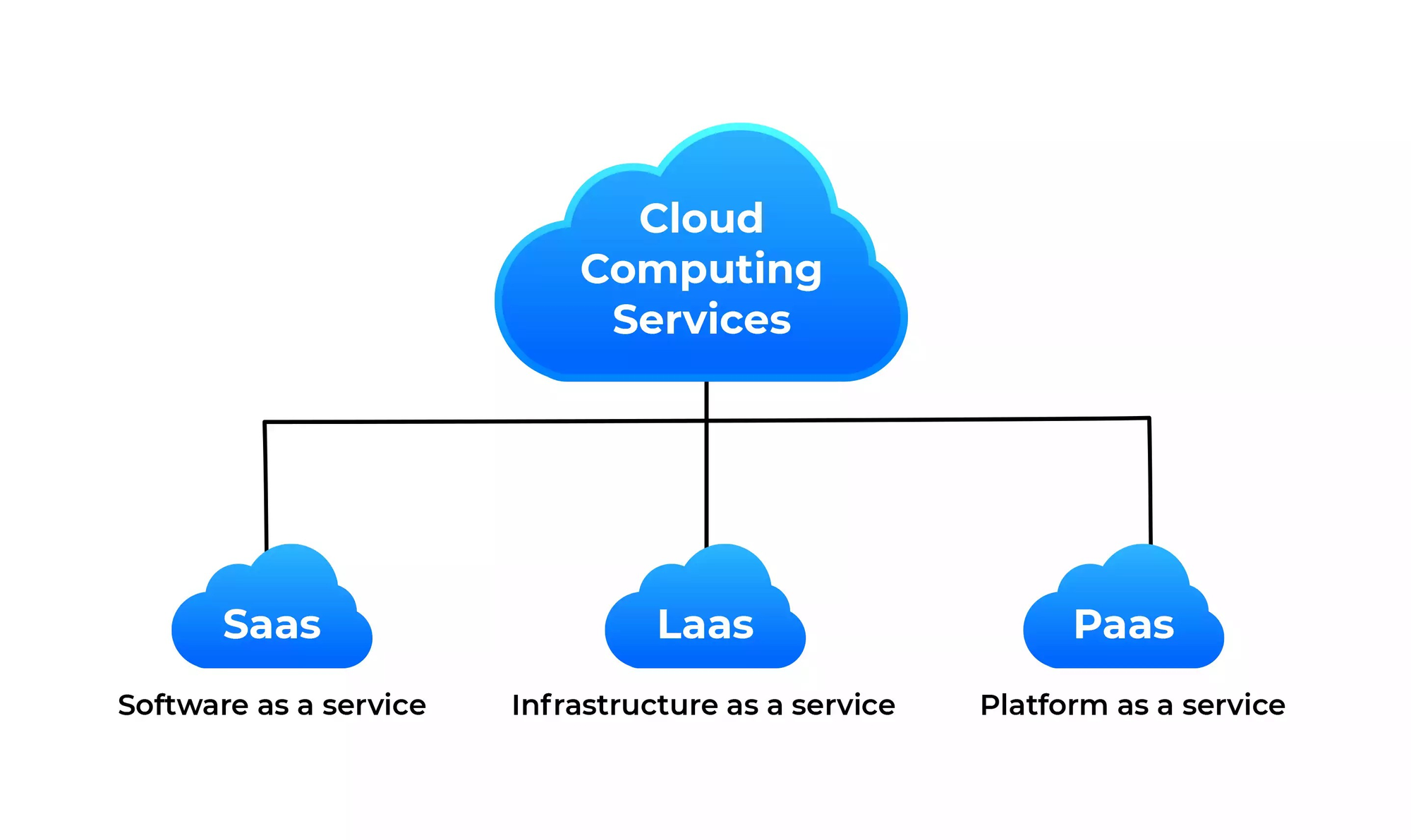
Gone are the days when scaling meant ordering new physical servers and waiting weeks for them to be delivered and set up. Cloud platforms like AWS, Google Cloud, and Azure have democratized access to enterprise-grade infrastructure.
But simply moving to the cloud isn't enough. You need to architect your application to take full advantage of cloud capabilities. This means embracing concepts like:
- Auto-scaling: Configure your application to automatically add or remove resources based on demand. This ensures you're not overpaying for idle resources during quiet periods, but can still handle sudden traffic spikes.
- Serverless computing: For certain workloads, serverless platforms like AWS Lambda or Google Cloud Functions can be a game-changer. They allow you to run code without provisioning or managing servers, scaling automatically with your usage.
- Managed services: Take advantage of managed database services, caching layers, and other cloud-native offerings. These services handle much of the operational overhead for you, allowing your team to focus on building features rather than managing infrastructure.
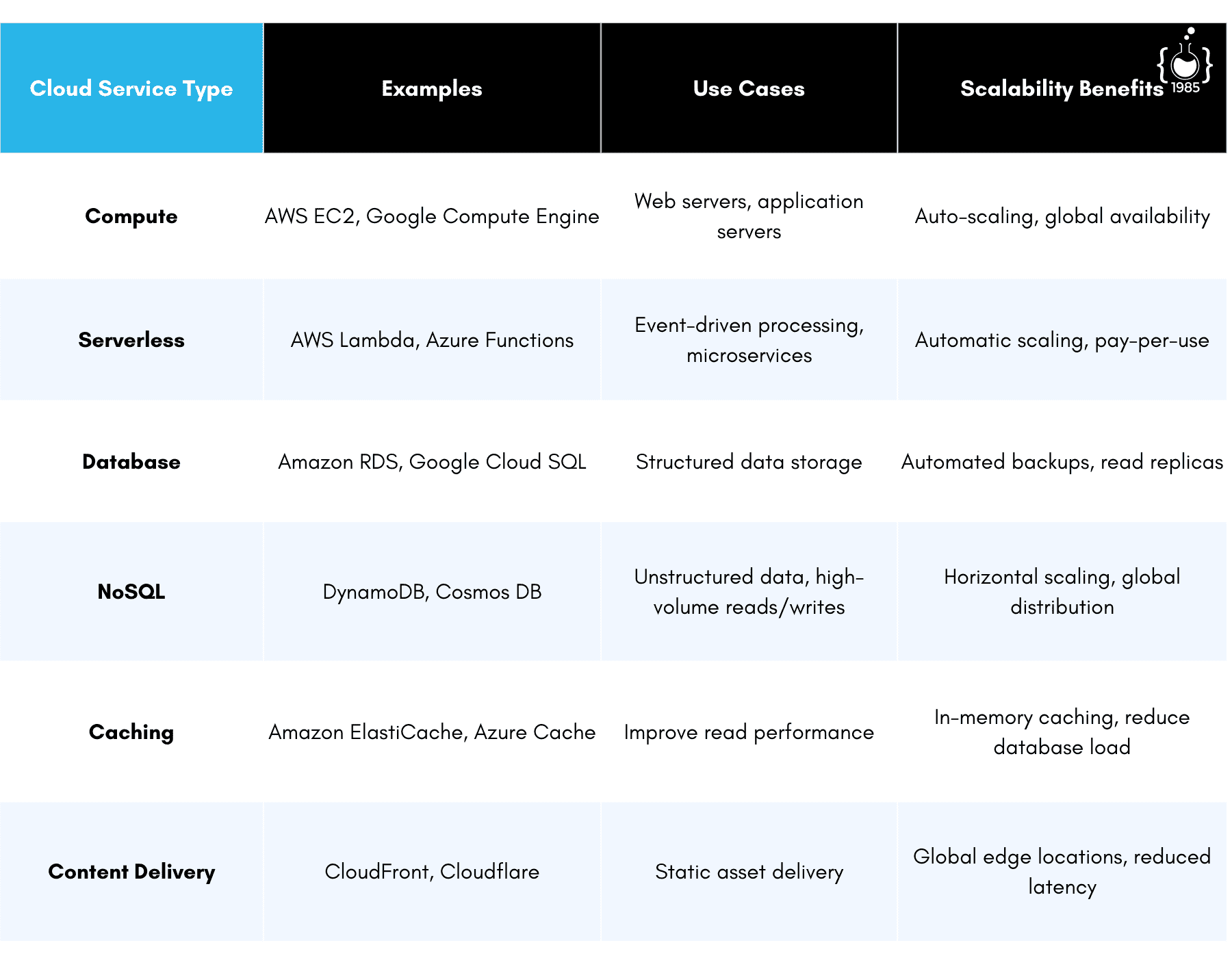
We worked with a media streaming startup that initially tried to build everything from scratch. They spent months setting up and tuning their own database clusters, caching systems, and content delivery networks. By the time they were ready to launch, they were already behind schedule and over budget.
We helped them pivot to a cloud-native architecture, using managed services wherever possible. They switched to Amazon RDS for their databases, ElastiCache for caching, and CloudFront for content delivery. This not only accelerated their time to market but also dramatically reduced their operational overhead. When they experienced a surge in users after being featured in a popular tech blog, their infrastructure scaled seamlessly to handle the load.
Data is The Lifeblood of Your Application
As your application scales, so does your data. And trust me, data scaling challenges can sneak up on you faster than you'd expect. Here are some key considerations:
Database Choice: SQL vs. NoSQL
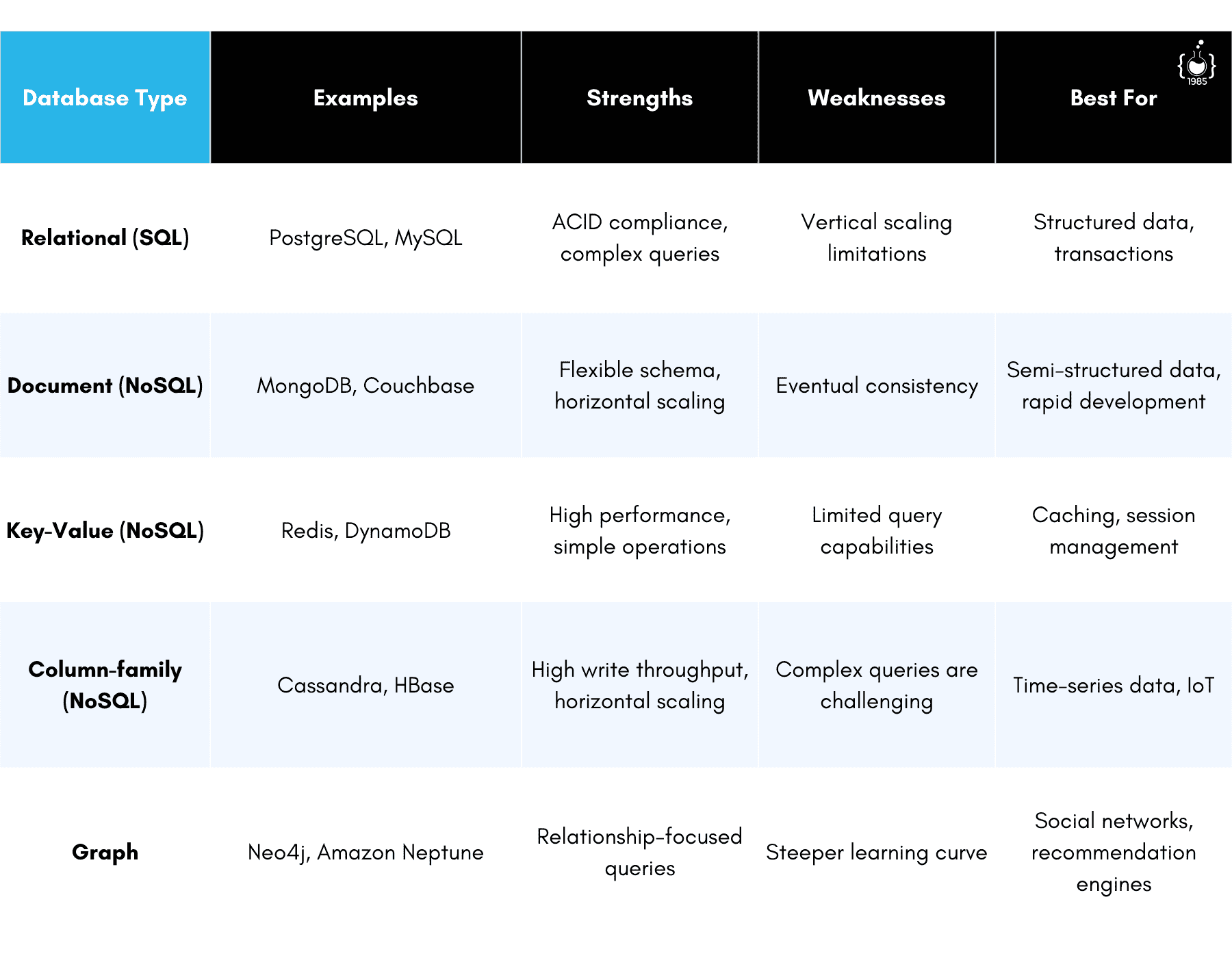
The age-old debate of SQL vs. NoSQL databases is really about choosing the right tool for the job. While traditional relational databases like PostgreSQL or MySQL are great for maintaining data integrity and handling complex relationships, they can struggle with extreme scale.
NoSQL databases like MongoDB or Cassandra, on the other hand, can handle massive amounts of unstructured data and scale horizontally with ease. But they come with their own set of challenges, particularly around data consistency and complex queries.
In my experience, a hybrid approach often works best. Use SQL databases for data that requires strong consistency and complex relationships, and NoSQL for high-volume, less structured data.
For instance, we worked with a social media analytics company that was struggling with performance as their data grew. They were storing all their data, from user profiles to post metrics, in a single PostgreSQL database. We helped them transition to a hybrid model:
- User profiles and relationships: Kept in PostgreSQL for ACID compliance and complex querying.
- Post content and metrics: Moved to MongoDB for its ability to handle unstructured data and scale horizontally.
- Real-time analytics: Implemented Cassandra for its ability to handle high write loads and time-series data.
This approach allowed them to scale their data infrastructure to handle millions of posts per day while maintaining the ability to perform complex analysis on user relationships and behaviors.
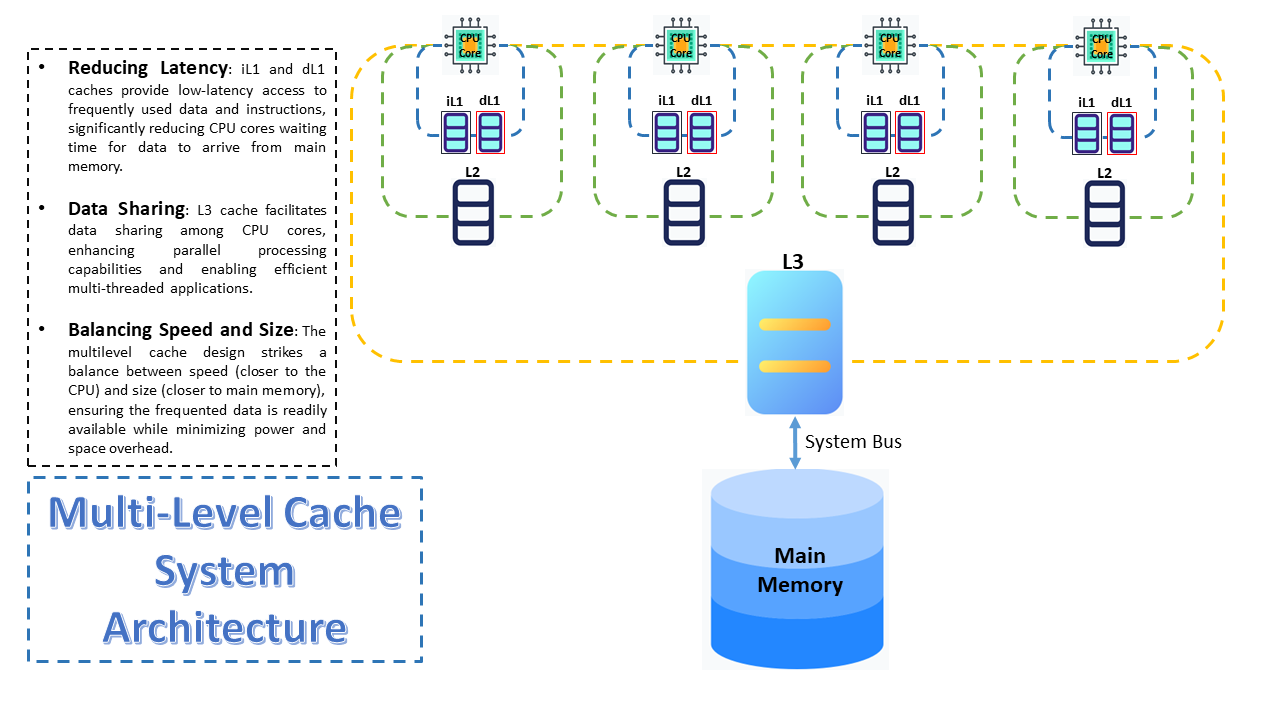
Caching: Speed and Scale
As your user base grows, database reads can become a major bottleneck. Implementing a robust caching strategy is crucial for maintaining performance at scale. Tools like Redis or Memcached can dramatically reduce the load on your database and speed up response times.
But caching isn't just about throwing Redis in front of your database and calling it a day. You need to think carefully about your caching strategy:
- What to cache: Identify your most frequently accessed and computationally expensive data.
- Cache invalidation: Determine how and when to update cached data to prevent serving stale information.
- Cache hierarchies: Implement multi-level caching (e.g., application-level, distributed cache, CDN) for optimal performance.
We once worked with an e-commerce platform that was experiencing slow page load times during peak hours. Their product pages were making multiple database queries for each request, which quickly became unsustainable as traffic grew.
We implemented a multi-level caching strategy:
- Application-level caching for user sessions and frequently accessed metadata.
- Redis for caching product details, with careful invalidation strategies to ensure data freshness.
- CDN caching for static assets and fully rendered pages for anonymous users.
This approach reduced their average page load time from over 2 seconds to under 200ms, even during their busiest sales periods.
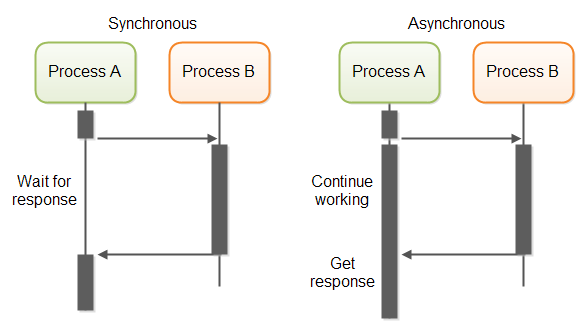
Asynchronous Processing
As your application scales, long-running tasks can become a major bottleneck. Whether it's processing a large batch of data, generating reports, or sending out thousands of emails, these tasks can slow down your application and impact user experience.
The solution? Asynchronous processing. By offloading time-consuming tasks to background workers, you can keep your main application responsive and scale your processing independently.
Tools like RabbitMQ, Apache Kafka, or cloud services like AWS SQS provide robust message queuing capabilities that allow you to build resilient, scalable asynchronous processing systems.
I remember working with a project management tool that was struggling with generating large PDF reports. As their user base grew, these report generation tasks were taking longer and longer, sometimes timing out for their largest clients.
We refactored their system to use asynchronous processing:
- When a user requests a report, instead of generating it on the spot, we create a task in a queue.
- A pool of worker processes constantly checks this queue for new tasks.
- When a worker picks up a task, it generates the report in the background and stores it in cloud storage.
- Once the report is ready, the user receives a notification with a download link.
This approach not only solved their timeout issues but also allowed them to easily scale their report generation capacity by simply adding more worker processes during peak times.
Monitoring and Observability
As your infrastructure grows more complex, the ability to understand what's happening in your system becomes crucial. You need to invest in robust monitoring and observability tools from day one.
Monitoring tools like Prometheus, Grafana, or cloud-native solutions like AWS CloudWatch give you visibility into your system's health and performance. But don't stop at just collecting metrics. Set up meaningful alerts that can notify you of potential issues before they become critical problems.
Observability goes a step further, giving you the ability to understand the internal state of your system by examining its outputs. Tools like Jaeger for distributed tracing, or ELK stack (Elasticsearch, Logstash, Kibana) for log aggregation and analysis, can be invaluable for debugging complex issues in a distributed system.
We once helped a client diagnose a particularly nasty performance issue that only occurred sporadically under high load. By implementing distributed tracing across their microservices, we were able to identify a subtle race condition in one of their services that was causing cascading failures under certain conditions. Without these observability tools, finding this issue would have been like searching for a needle in a haystack.
Security: Baked In, Not Bolted On
In the rush to build and scale, security can often take a back seat. But in today's world of increasing cyber threats and data privacy regulations, security needs to be a first-class citizen in your infrastructure from day one.
This means:
- Implementing strong authentication and authorization mechanisms.
- Encrypting data both in transit and at rest.
- Regularly updating and patching your systems.
- Implementing network segmentation and firewalls.
- Conducting regular security audits and penetration testing.
But beyond these basics, you need to foster a culture of security awareness within your development team. Encourage practices like threat modeling during the design phase of new features, and make security reviews a standard part of your code review process.
We worked with a healthcare startup that was preparing for rapid growth. Given the sensitive nature of their data, security was paramount. We helped them implement a comprehensive security strategy that included:
- End-to-end encryption for all patient data.
- Multi-factor authentication for all user accounts.
- Regular automated security scans of their infrastructure and code.
- A bug bounty program to incentivize responsible disclosure of vulnerabilities.
This proactive approach to security not only protected their users' data but also became a key differentiator in their market, helping them win contracts with major healthcare providers.
The Journey of Scalability
Building a scalable tech infrastructure is not a one-time task, but an ongoing journey. It requires foresight, careful planning, and a willingness to continuously learn and adapt. The technologies and best practices I've outlined here are not silver bullets, but rather tools in your arsenal. The key is to understand the principles behind them and apply them judiciously to your specific use case.
Remember, scalability isn't just about handling more users or data. It's about building a system that can grow and evolve with your business needs. It's about creating an infrastructure that empowers your team to innovate rapidly and confidently.
As you set out on your journey to build a scalable tech infrastructure, keep these principles in mind:
- Think big, but start smart. Design for scale from day one, but don't over-engineer.
- Embrace modularity and loose coupling. It'll make your life easier as you grow.
- Embrace the cloud, but understand its nuances.
- Make data management a first-class concern.
- Asynchronous processing is your friend.
- You can't improve what you can't measure. Invest in monitoring and observability.
- Security is not an afterthought. Bake it into your infrastructure from the start.
Building a scalable infrastructure is challenging, but it's also incredibly rewarding. It's about creating a foundation that can support your wildest ambitions, no matter how big your dreams grow. So dream big, plan carefully, and build for the future. Your future self (and your ops team) will thank you.


