AI Agent Intelligence: Beyond the Basics
Discover the blueprint for building powerhouse AI agents, from data pipelines to microservices - practical, punchy, and made for real-world impact


My team and I spend our days building all kinds of systems: big, small, and everything in between. But there’s one thing that keeps us on our toes lately - AI agents.
They’re everywhere right now, from automated chatbots to industrial control systems. It’s a pretty big deal. Companies come to us asking, “How do we go beyond off-the-shelf AI solutions?” They’re no longer satisfied with basic web scrapers or answering a few questions on a helpdesk. They want more. They want dynamic intelligence. They want the best.

So here we are. Today, I’m writing a deep-dive. I’ll skip the usual “AI will change the world” pitch and get into the real stuff. We’ll talk about architecting AI agents for enterprise use, the code involved, and how to tweak performance until it sings. If you like code snippets, you’re in for a treat. We’ll have some right here, straight from the trenches.
Why Enterprise-Grade Matters
Most consumer-grade AI systems might be okay at first. Simple chatbots that respond to queries or small recommendation engines that pick products. But enterprises need more. They need rigor, reliability, and robust performance.
I’ve seen big companies with billions in revenue suffer because their AI was set up in a hurry. They ended up with downtimes, chaotic data pipelines, or unreliable predictions. Then they called us. We learned a valuable lesson: if you can’t trust the AI agent at scale, it’s not worth having at all.
That’s why enterprise-grade AI isn’t just about accuracy. It’s about governance. It’s about building an agent that respects compliance, handles spiky traffic, and recovers gracefully when something breaks. It’s about bridging advanced math with robust software design. It’s about building trust.
Laying the Foundations
Before we build something robust, we need to understand what an AI agent really is. I’m not talking about a chatbot that just echoes your question. I’m talking about an autonomous or semi-autonomous system that can interpret tasks, interact with data, and act on your behalf.
Building Blocks
At a high level, enterprise AI agents blend together three main components:
- Perception: The agent’s ability to sense data—natural language, images, or structured streams.
- Reasoning: A core logic system (often a deep learning model combined with rules) that interprets, plans, and decides what to do next.
- Action: The outward-facing interface, whether it’s generating content, controlling software, or orchestrating tasks in a system.
A simple example is a helpdesk AI that reads a user’s issue from an email, processes relevant knowledge base documents, then issues a concise, context-rich response. But the real kicker is how it’s built.
It’s More Than a Model
One common misconception is that an AI agent equals “just a model.” Nothing could be further from the truth. In practice, an agent includes:
- Data Ingestion Pipelines: Regularly pulling, cleaning, and validating data from various sources—APIs, internal DBs, or streaming data.
- Neural Network or Classical ML Pipeline: This could be a large language model (LLM) like GPT, or it might be a carefully tuned random forest or XGBoost model.
- Orchestration Layer: This is the backbone that glues everything together. It also handles scaling, load-balancing, and concurrency.
- Monitoring and Feedback Loops: Observing outputs, re-routing errors, and re-training or fine-tuning based on usage patterns.
Getting these pieces right at enterprise scale is an art. And it’s easy to botch it if you treat it like a weekend hackathon.
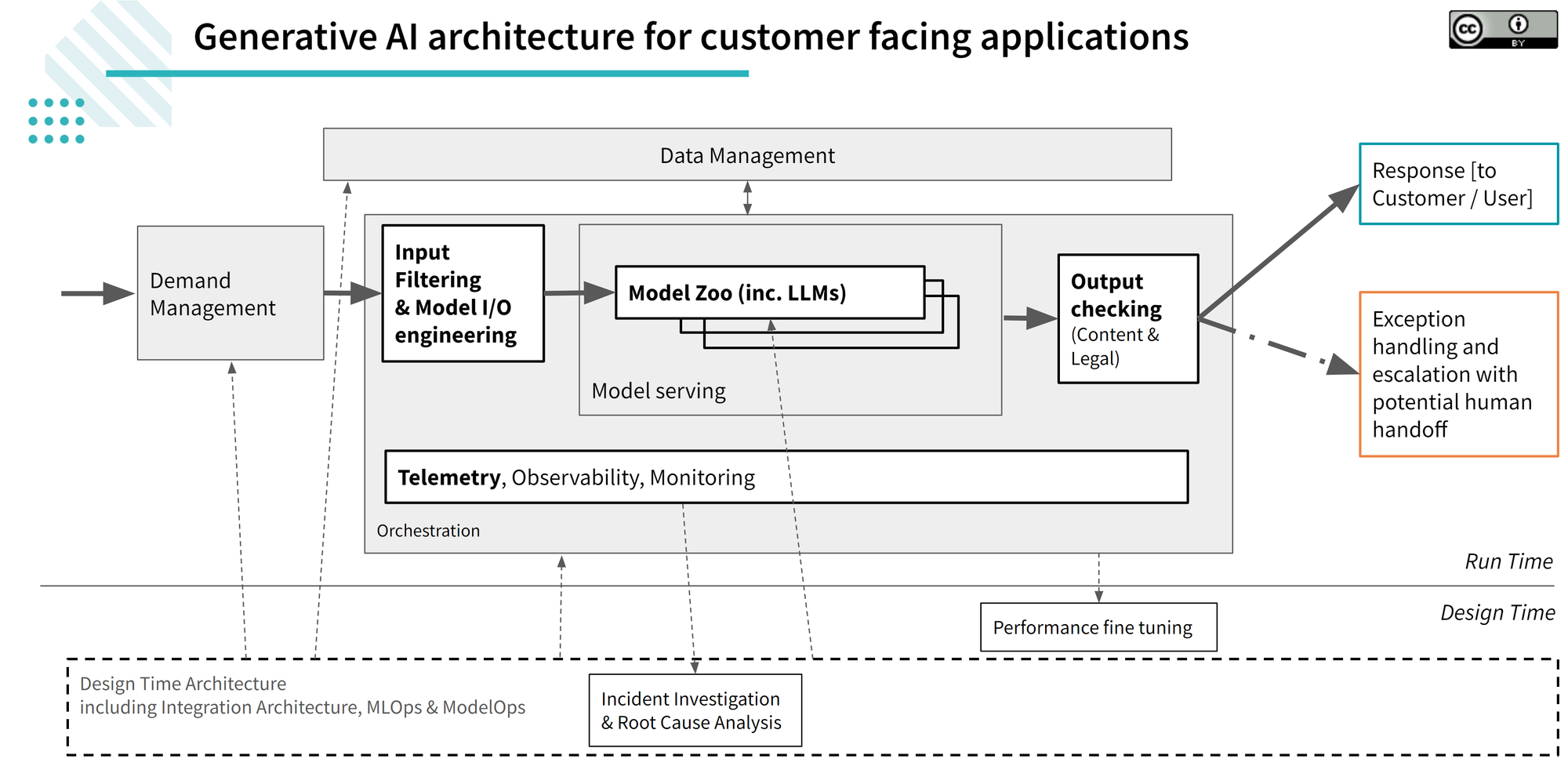
Architecting Enterprise-Grade AI Agents
So how do you architect an enterprise-level AI agent? If you came here for code, we’ll get there soon. But first, let’s talk architecture.

Core Components
An enterprise AI agent, especially one designed for tasks like predictive maintenance or advanced document comprehension, involves these crucial elements:
- Data Flow and Storage
- A reliable data pipeline (ETL or ELT).
- Distributed storage solutions like AWS S3 or GCP’s Cloud Storage for scale.
- Real-time integration with message queues (Kafka, RabbitMQ).
- Model Serving
- Containerized model deployments (Docker, Kubernetes).
- Load-balancing across multiple GPU instances or CPU clusters.
- Autoscaling based on demand, to handle traffic spikes.
- Agent Logic Layer
- Sometimes referred to as the “brains,” this layer orchestrates multiple sub-models.
- It might chain prompts (if using LLMs) or pass intermediate results between multiple specialized models.
- This can be done using frameworks like Ray Serve, NVIDIA Triton, or custom microservices.
- Interaction and Interface
- APIs, webhooks, or gRPC endpoints to connect to the outside world.
- Real-time dashboards for analytics and alerts.
- DevOps integration for continuous deployment and monitoring.
- Observability and Governance
- Logging, tracing, and metrics with tools like Prometheus, Grafana, or Datadog.
- Audit trails and compliance checks (HIPAA, GDPR).
- Feedback loop from actual usage to trigger re-training.
Data: The Heart and Soul
Data is the lifeblood of your AI agent. Dirty data leads to dirty predictions. And, yes, we’ve had more than a few laughs (and tears) dealing with this. For enterprise agents, you can’t just dump everything into a CSV and call it a day.
- Structured vs. Unstructured: You might have structured sales data in an RDBMS. Then you have unstructured data like PDFs, Slack messages, or sensor logs. Each of these must be treated differently.
- Quality Assurance: Implement strict data validation checks. If you train your AI on garbage, the AI will act like garbage.
- Scalability: Tools like Apache Spark or Databricks can help process huge volumes of data in parallel.
It sounds obvious, but I can’t stress enough how many times we’ve rescued clients who overlooked data engineering. If you’re building an enterprise AI agent, start with bulletproof data pipelines.
Real Code Example: A Simplified Orchestration Layer
Below is a simplified Python snippet that shows how you might orchestrate tasks within an AI agent. Note that in real life, you’d use separate modules, packages, and Docker microservices. But here’s a taste:
import asyncio
import aiohttp
async def fetch_data(session, url):
"""Fetch data from a given URL"""
async with session.get(url) as response:
if response.status != 200:
raise ValueError(f"Request failed with status {response.status}")
return await response.json()
async def process_data(data):
"""Apply some data transformations"""
# Example transformation
return [item for item in data if item.get('relevant')]
async def run_inference(model, preprocessed_data):
"""Run inference on the data using a loaded model"""
# For demonstration, let's pretend we do something heavy
results = []
for item in preprocessed_data:
# In real code, this might call a deep learning model
# e.g., results.append(model.predict(item))
results.append(f"InferenceResult_{item.get('id')}")
return results
async def main():
model = "Pretend this is a loaded model object"
urls = ["https://api.example.com/data_part1",
"https://api.example.com/data_part2"]
async with aiohttp.ClientSession() as session:
# Data ingestion
tasks = [fetch_data(session, url) for url in urls]
raw_data_parts = await asyncio.gather(*tasks)
# Concatenate data from multiple sources
combined_data = []
for data_part in raw_data_parts:
combined_data.extend(data_part)
# Data processing
preprocessed_data = await process_data(combined_data)
# Run inference
inference_results = await run_inference(model, preprocessed_data)
print("Inference complete. Results:")
for res in inference_results:
print(res)
if __name__ == "__main__":
asyncio.run(main())
Here’s what’s happening:
- Concurrent Data Fetching: We use
asyncioandaiohttpto pull data from multiple APIs simultaneously. This is crucial for large-scale systems. - Data Processing: We do some basic filtering or transformation. In reality, you’d do more complex tasks, perhaps with PySpark or specialized ETL workflows.
- Inference: We pretend to load a model and run inference. In a real scenario, you’d connect to a GPU-accelerated server or a specialized microservice.
This snippet isn’t “production-ready,” but it illustrates the concurrency mindset needed. Enterprises often do this at scale, with many more fail-safes and advanced logging in place.
Performance Optimization Techniques
AI agents can be resource hogs. Especially if you’re dealing with large language models or real-time image processing. Below are some performance optimization tactics we’ve used at 1985 to keep AI agents running smoothly.
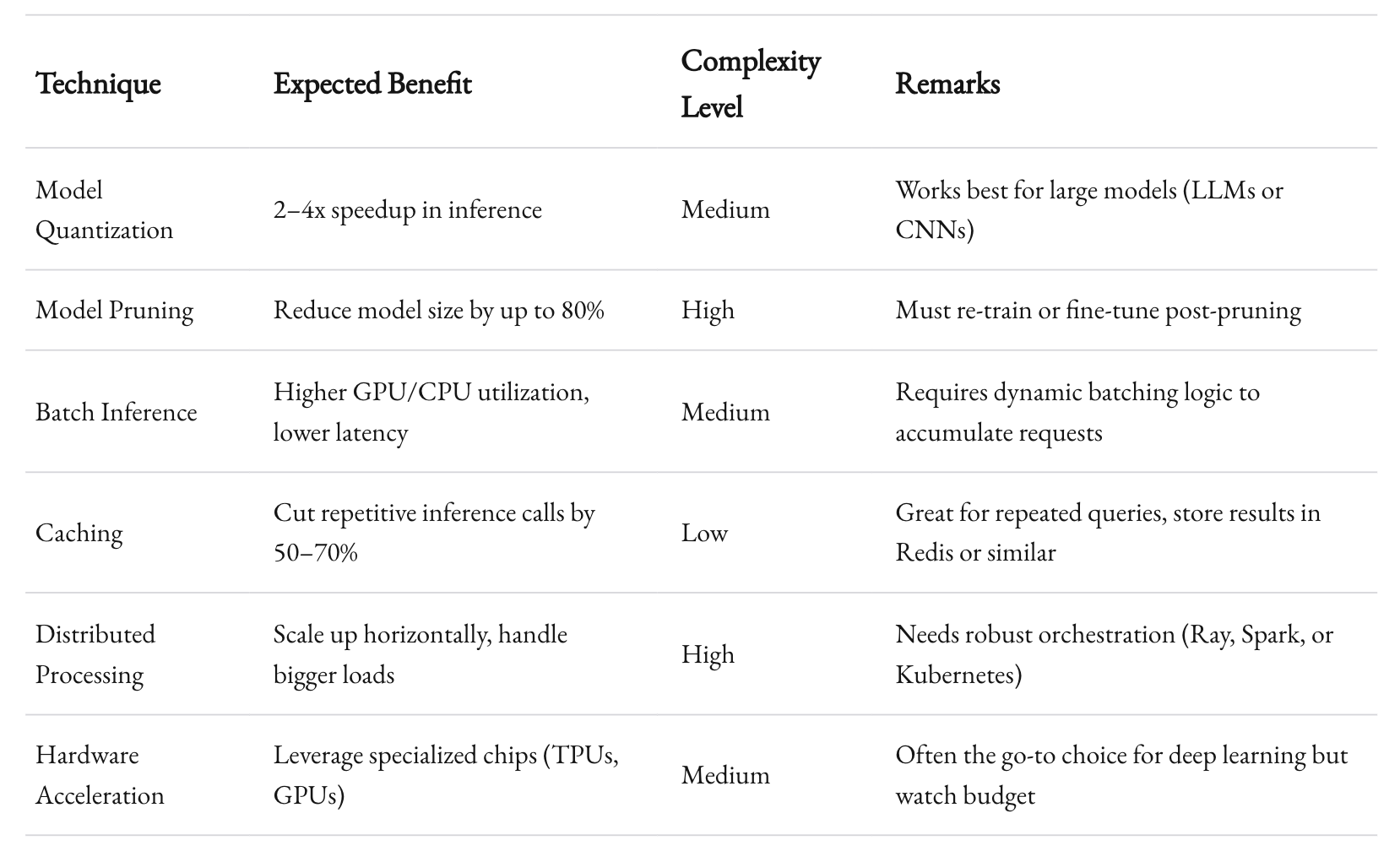
1. Model Quantization and Pruning
Deep neural networks can be huge. For instance, GPT-3.5 has 175 billion parameters. If your enterprise doesn’t need that scale, or if you have a specialized domain, you can reduce model complexity.
- Quantization: Convert weights from 32-bit floats to 8-bit integers or even lower. NVIDIA’s TensorRT or Intel’s OpenVINO can help with this.
- Pruning: Remove redundant weights or neurons without losing much accuracy. Some advanced libraries let you systematically prune networks, then fine-tune them back.
According to a study in IEEE Transactions on Neural Networks and Learning Systems (2021), well-pruned networks can retain 95% of the original accuracy while reducing the model size by 80%. That’s a big deal for enterprise resource usage.
2. Efficient Batch Processing
Batching can dramatically speed up inference. Rather than sending one request at a time, your AI agent can bundle multiple inputs into a single batch. GPUs are designed for parallel operations, so feed them in parallel.
But be careful. If you wait too long to accumulate a big batch, you add latency. So there’s a sweet spot. We often do micro-batches (like 8–32 items) for real-time systems, balancing throughput with latency.
3. Caching
Cache your intermediate results. If an enterprise AI agent processes the same user query multiple times, store the result in Redis or Memcached. This is especially useful for content generation tasks where the same query might appear again.
We once built a customer support agent that kept receiving identical questions about password resets. By caching the responses, we trimmed 70% of the overall compute load.
4. Distributed Computing
Some tasks just can’t be done on a single machine. That’s where distributed frameworks like Apache Spark, Ray, or Horovod come in. Splitting huge datasets or parallelizing the inference across multiple nodes can make or break your SLA.
The key is not to jump into distributed everything. Start with a single node or GPU, optimize it thoroughly, then scale out as needed. Over-engineering from day one can lead to complexity that’s hard to manage.
Example: Benchmarking Different Concurrency Approaches
Below is a small table comparing three concurrency approaches for a hypothetical text classification model. Let’s assume we have to classify 1,000 requests per second at peak.
| Concurrency Approach | Implementation | Avg Latency | Throughput | Complexity |
|---|---|---|---|---|
| Sync (Thread Pool) | Python’s concurrent.futures thread pool |
~150ms | 900 req/s | Moderate |
| Async (asyncio) | Python’s asyncio + aiohttp |
~100ms | 1100 req/s | Moderate |
| Actor Framework | Ray or Dask Actors | ~90ms | 1200 req/s | High |
Key Takeaways:
- A standard synchronous ThreadPoolExecutor can handle a decent load but has higher latency.
- Pure async solutions in Python yield better throughput and slightly lower latency.
- Actor frameworks like Ray often perform better but come with added complexity in deployment and maintenance.
Building Specialized AI Agents
At 1985, we’ve built AI agents for a variety of industries: healthcare, finance, e-commerce, and more. Let’s go beyond generic advice and talk specifics.
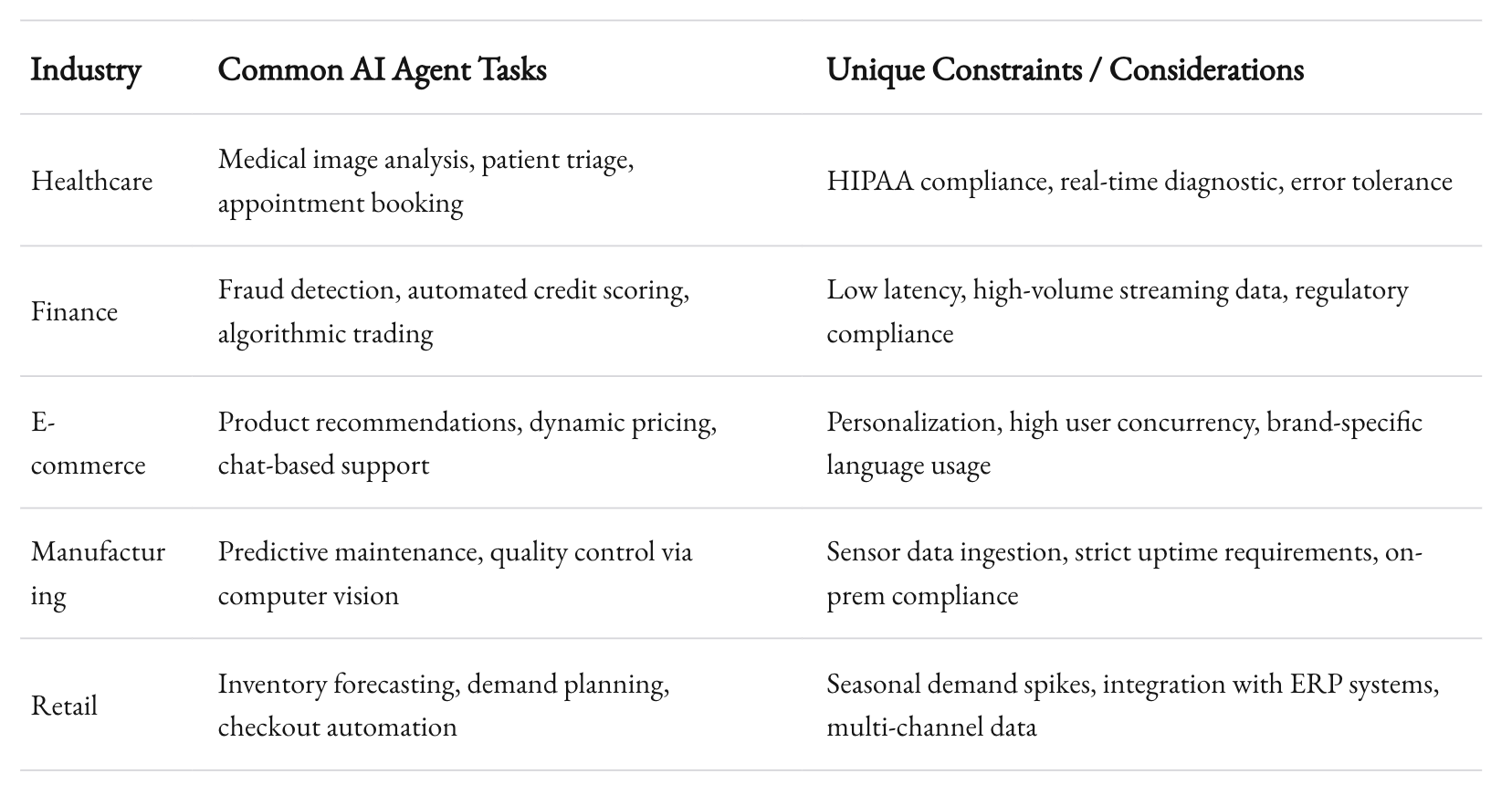
Healthcare Example
Use Case: Automating triage in a hospital setting.
- Challenge: The data is extremely sensitive (HIPAA compliance needed). The system must handle multiple data streams: patient records, sensor data, and doctors’ notes.
- Solution: We used a microservices architecture with strict access controls. We set up an on-prem GPU cluster for data processing to ensure data never leaves the hospital’s private network.
We pruned the BERT-based clinical model to reduce inference times by 40%. Real-time triage decisions now happen in under 2 seconds, on average.
Finance Example
Use Case: Fraud detection for a large fintech platform.
- Challenge: The agent must process thousands of transactions per second, cross-reference suspicious patterns, and respond in real-time with minimal false positives.
- Solution: We built a pipeline with Apache Kafka for streaming data ingestion, then used a specialized XGBoost model for classification.
We also integrated a real-time feedback loop. When the system flagged a transaction, human auditors reviewed it. Their actions (confirm fraud or not) retrained the model weekly. This iterative approach cut fraud-related losses by 27% in the first quarter.
The Fine-Tuning Process
An enterprise AI agent isn’t a one-and-done solution. Models drift. Data evolves. User expectations change. So fine-tuning is crucial.
Data Drift Detection
Set up mechanisms to track changes in input distribution. If your agent starts receiving more queries from a new region or a shift in user language, your model might underperform.
- Statistical Checks: Use population stability index (PSI) or KL-divergence to compare real-time data vs. training data distribution.
- Alerting: If the drift exceeds a threshold (like a 20% distribution shift), trigger a pipeline to retrain or prompt a data scientist to investigate.
Continuous Learning
Modern ML Ops is about iteration. In finance, we had a system that re-trained nightly on the latest transactions. In e-commerce, we re-trained a recommendation system weekly to capture new products and user behavior.
The trick is to decide on your schedule. Retraining every day can be overkill if your data changes slowly. Then again, if your domain is very dynamic, nightly or even hourly re-training could be your best bet.
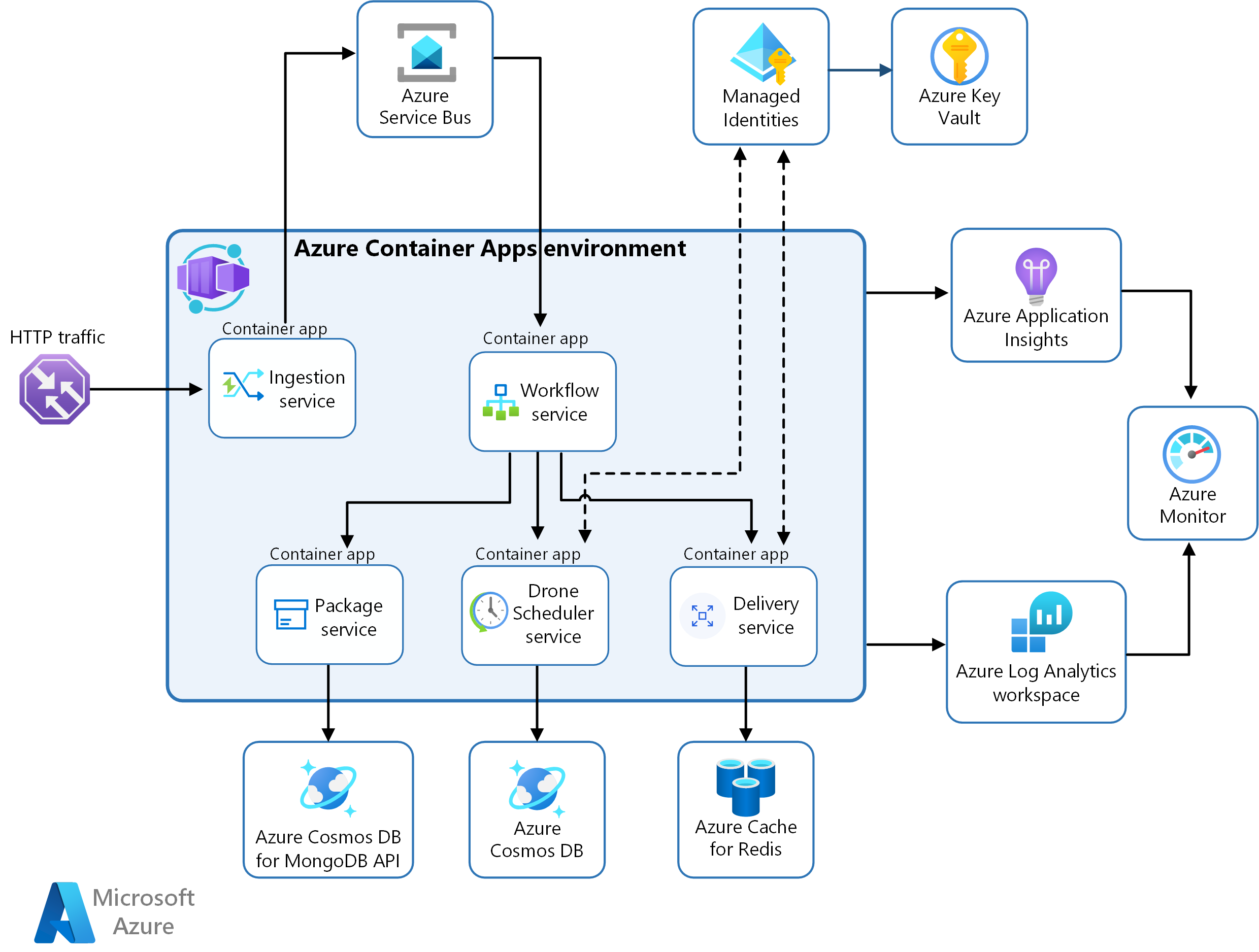
Advanced Orchestration with Microservices
Big enterprises rarely settle for a single monstrous codebase. They break it down into microservices. Each microservice does one thing well—data ingestion, model serving, or result aggregation. That’s how you keep systems modular and scalable.
Example Architecture
+------------+ +------------------+
| Frontend | <--------> | API Gateway |
+------------+ +------------------+
| ^
v |
+--------------+----------------+
| Microservice: Data Fetch |
+--------------+----------------+
| ^
v |
+--------------+----------------+
| Microservice: Model Serving |
+--------------+----------------+
| ^
v |
+--------------+----------------+
| Microservice: Results |
+--------------+----------------+
|
v
+--------------+
| Database |
+--------------+
Each microservice communicates via REST, gRPC, or message queues (Kafka/RabbitMQ). This pattern is especially common when different teams own different parts of the pipeline.
Pros and Cons
- Pros: Scalability, fault isolation, easier maintenance.
- Cons: Communication overhead, added complexity, and the need for robust monitoring.
From my experience, microservices are a must for big companies with varied data sources and use cases. They can be overkill for smaller setups, though, so pick wisely.
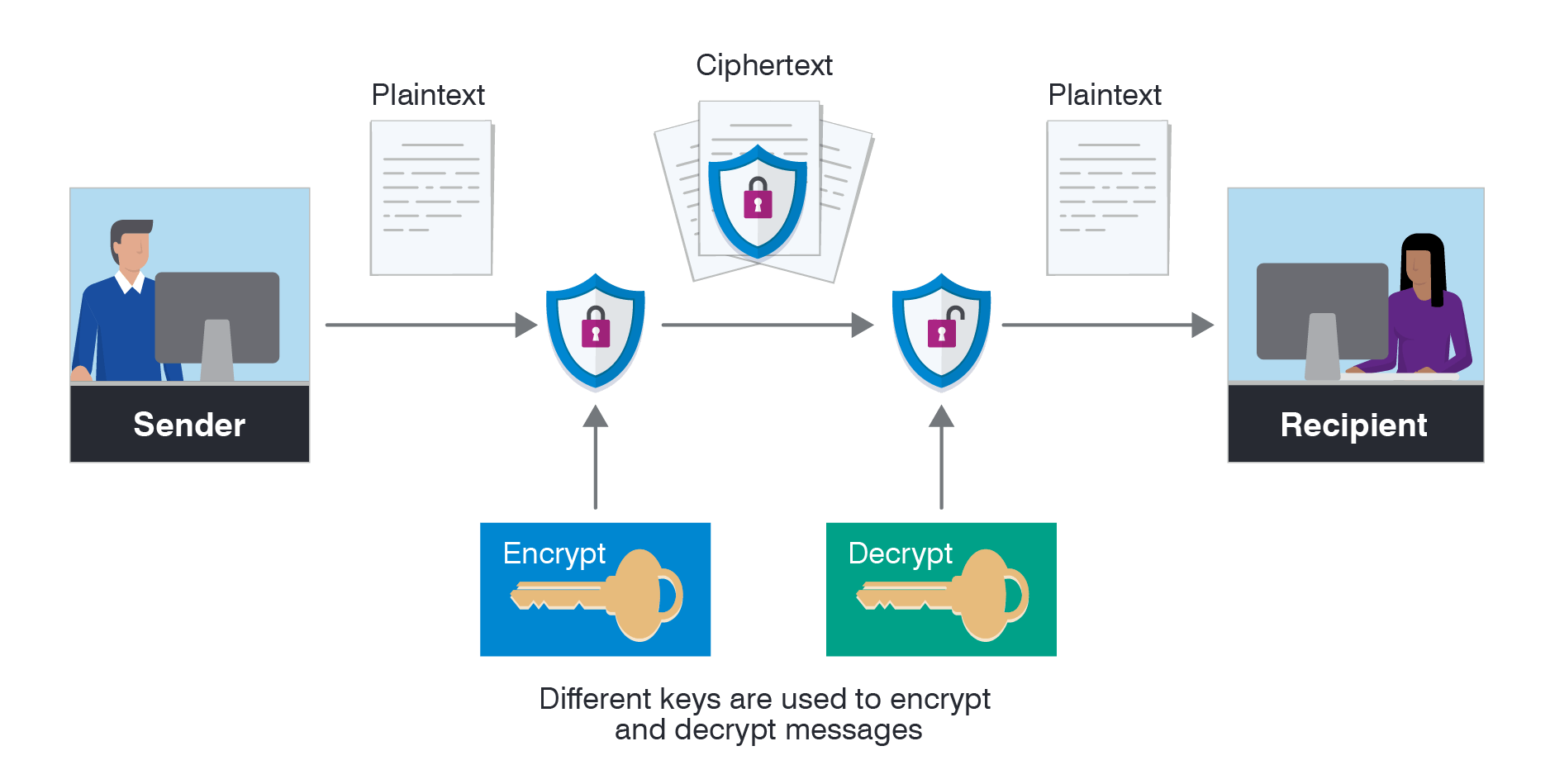
Security and Compliance
Yes, AI is fun and all. But if you’re dealing with an enterprise environment, security is non-negotiable. We’re talking encryption at rest, encryption in transit, and rigorous policy enforcement.
Encryption
- Data in Transit: Use TLS 1.2 or higher.
- Data at Rest: Encrypt using AES-256.
Identity and Access Management (IAM)
Controlling who can access the AI agent is crucial. We often integrate with an enterprise’s existing IAM solutions—Active Directory, Okta, or custom SSO.
Regulatory Compliance
If you’re in healthcare, you’re dealing with HIPAA. In finance, you’ve got PCI-DSS. For any EU data, there’s GDPR. The AI agent must log who accessed which data, when, and why.
Putting It All Together: A Day in the Life of an AI Agent
Let’s trace a hypothetical day in the life of an enterprise AI agent. Imagine a system that processes insurance claims:
- Morning: The AI agent ingests a large batch of overnight claims data from various hospitals and service providers. It runs data validation and merges everything into a standard format.
- Midday: The system starts receiving real-time queries from insurance reps. Some claims get flagged for fraud. The AI agent triggers a specialized sub-module that checks for known fraud patterns.
- Afternoon: The data science team notices a new type of claim causing classification errors. They update the data pipeline to handle these new fields. The model is retrained with fresh examples.
- Evening: Management runs daily analytics. The AI agent surfaces key insights: average claim payout, processing times, and suspicious outliers.
- Night: Automated scripts archive older data, refresh indexes, and prepare next day’s training. The cycle continues.
Everything works in synergy. Data flows. Models infer. Microservices communicate. Observability tools keep watch, ready to alert if anomalies appear. That’s a robust enterprise AI agent in action.
Code Example: Simple Microservice with FastAPI
To give you another taste of code, here’s a snippet showing how you might set up a microservice using FastAPI for inference. This is just the “model serving” piece in a microservices ecosystem.
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
import uvicorn
app = FastAPI()
# Pretend model
class SimpleModel:
def predict(self, data):
return f"Predicted_{data}"
model = SimpleModel()
class PredictionRequest(BaseModel):
input_data: str
@app.post("/predict")
def predict(request: PredictionRequest):
if not request.input_data:
raise HTTPException(status_code=400, detail="No input data provided.")
result = model.predict(request.input_data)
return {"result": result}
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)
What’s going on?
- We define a
SimpleModelto mimic a loaded AI model. - We define a
PredictionRequestschema so the API knows what to expect as input. - The
/predictendpoint returns a JSON response with the prediction.
In a real environment, you’d load a big model from a serialized file or a specialized inference runtime. You’d also add metrics, logging, and robust error handling.
Monitoring and Alerting
Running an enterprise AI agent without proper monitoring is like driving with your eyes closed. So how do you keep an eye on everything?
Metrics to Watch
- Inference Latency: Keep track of how long each prediction takes.
- Throughput (RPS): How many requests are being handled per second.
- Resource Utilization: GPU/CPU usage, memory, and network I/O.
- Error Rates: HTTP 5xx errors, model inference exceptions, timeouts.
Tools
- Prometheus + Grafana: A popular stack for time-series metrics and dashboards.
- Datadog: Offers monitoring, tracing, and logs in a single platform.
- ELK Stack (Elasticsearch, Logstash, Kibana): Great for ingesting logs and analyzing them in near real-time.
A typical enterprise AI setup uses a combination of these. For instance, Grafana for real-time dashboards, Datadog for distributed tracing, and an ELK stack for historical log analysis.
Scaling Up Responsibly
As your AI agent grows, you’ll face new challenges. You’ll get more users, more data, and more complex tasks. That growth is exciting, but it can also be stressful if you don’t have a plan.
Horizontal and Vertical Scaling
- Vertical Scaling: Throw bigger machines or GPUs at the problem. This works to a point, but hardware has limits—and costs a fortune.
- Horizontal Scaling: Distribute workloads across multiple machines. This approach is more flexible and often more cost-effective long term.
Kubernetes is a common solution for orchestrating containers across clusters. You can define autoscaling rules to spin up more pods during peak hours. That means your AI agent can handle spikes without melting down.
Multi-Region Deployments
Large enterprises often run their AI agents across multiple data centers or cloud regions. That way, if one region goes down, another can keep things running. Multi-region setups also reduce latency for users in different parts of the world.
Overcoming Common Pitfalls
After building AI agents for years, I’ve seen a few pitfalls repeat themselves. Here are some that crop up all too often:
- Ignoring Data Quality
- We’ve had clients say, “Our data is messy, but the model will handle it, right?” No. It won’t.
- Underestimating Governance
- Audits can come knocking. If your AI decisions can’t be traced or explained, that’s a problem.
- Over-Reliance on Off-the-Shelf Models
- GPT or BERT might be good for general tasks, but your domain might need specialized fine-tuning.
- Haphazard Monitoring
- If you don’t know your model performance in real time, you’ll find out only when something crashes.
Staying ahead of these pitfalls means designing with caution from day one.
Recap
Building enterprise-grade AI agents is no cakewalk. It’s a blend of data engineering, model optimization, orchestration, security, and a good dose of real-world resilience. It’s about more than just being cutting-edge. It’s about delivering consistent, trustworthy performance in high-stakes environments.
I know it can be daunting. But trust me, the results are worth it. Properly architected AI agents can transform your operations, cut costs, and open new business possibilities. At 1985, we’ve seen it firsthand: from hospitals making faster clinical decisions to finance giants slashing fraud. It’s thrilling to watch an agent you built handle millions of tasks without blinking.
One last tip: stay curious. The AI landscape evolves quickly. New frameworks, new hardware accelerators, and new optimization techniques appear almost monthly. Keep reading, keep testing, and keep refining your approach. If you get stuck—or if you need an extra hand—reach out. My team at 1985 thrives on these challenges.
Thanks for reading this deep-dive. I hope it gave you fresh insights into the art and science of enterprise-grade AI agents. Go forth and build something amazing. And remember: AI is only as strong as the foundation beneath it. Make it solid.


